
Code Smell Detection using Machine Learning Classification Algorithm
- Law Teng Yi
- 889-900
- Jun 5, 2024
- Education
Code Smell Detection using Machine Learning Classification Algorithm
Law Teng Yi
Faculty of Computer Science and Information Technology, New Era University College, Kajang, Malaysia
DOI: https://dx.doi.org/10.47772/IJRISS.2024.805063
Received: 22 April 2024; Revised: 01 May 2024; Accepted: 06 May 2024; Published: 05 June 2024
ABSTRACT
Code smell indicates a poor implementation choice that affects software quality attributes (Pérez, 2013). Fowler (1999) also describes it as an internal code-level problem where the code becomes complex, the design broken, and eventually worsens software quality. Jose (2020) has reported that most applied existing approaches for code smells detection are search-based (30.1%), metric-based (24.1%), and symptom-based approaches (19.3%). However, these existing approaches can only apply to simpler detection; the greater the complexity of code smell, the lower the results for code smell detection (Mantyla M, 2004). Kessentini (2014) also has reported that detecting the problems of code smell is difficult and the performance is not effective using the existing approaches such as search-based, symptom-based, visualization-based, probabilistic, cooperative-based, manual, metrics-based, and rule-based. As a result, many of these approaches extend to the application of machine learning classifiers in software code smell detection. Fontana (2016) reported that a supervised machine learning strategy can be used to forecast the value of the dependent variable using machine learning classifiers to address the problem. In this project, we propose a machine learning supervised Gaussian processes algorithm for JAVA open-source code smell detection. The Gaussian process is a highly interpretable supervised machine learning algorithm used in regression testing to quantify prediction uncertainty. A code smell detection application prototype will be developed to implement the proposed work. The effectiveness of the proposed work in terms of detection accuracy will be evaluated further.
Keywords: Code Smell, Machine Learning classifiers, regression testing, Gaussian Process
INTRODUCTION
The phrase “smell” refers to an inherent issue in software, either at the code level (Fowler, 1999) or higher, characterizing symptoms noticed in components that impede software progress. Code smells are breaches of code design principles (Fowler, 2019), and they contribute to technical debt, impacting programmed maintenance and evolution. It is indisputable that the notion of smells was originally adopted by the agile software development community as a means of pointing out flaws or areas for improvement. This phrase is now used in the industry to describe anomalies in software components. According to Jose (2020), the most widely used existing ways for detecting code smells are search-based (30.1%), metric-based (24.1%), and symptom-based approaches (19.3%). However, current methodologies can only be used for simple detection; the larger the complexity of the code smell, the worse the results for code smell detection (Mantyla, 2004). Kessentini (2014) also reported that detecting the problems of code smells is difficult and the performance is not effective using existing approaches such as search-based, symptom-based, visualization-based, probabilistic, cooperative-based, manual, metrics-based, and rule-based.
A search-based technique is utilized at each phase to develop a solution by selecting the local best option from a pool of possibilities. Others construct a neighborhood of viable solutions, which are obtained by modifying the search-based approach. The quality of the solutions is assessed, and a candidate solution is chosen to be the current one. When the halting conditions are met, the current solution is returned. The search-based method generates a large sequence of refactorings as one solution without explaining to developers how the various operations in the solution are dependent on each other in terms of fixing specific quality issues or improving fitness functions, which can affect developers’ trustworthiness in practice.
LITERATURE REVIEW
Fowler and Beck (Fowler, 2000) identified and proposed higher levels of bad code smells taxonomy for classifying the classes. The classes are bloaters, object-orientation abusers, change preventers, dispensables, encapsulators, and couplers. Bloaters are instances of code that have grown so huge that they can no longer be handled efficiently. The Bloater category includes Long Method, Large Class, Primitive Obsession, Long Parameter List, and Data Clumps. Categories of Object-Orientation abuser have switch statements, temporary field, refused bequest, Alternative classes with different interfaces, and parallel inheritance hierarchies. Because the Alternative Classes with Different Interfaces smell lacks a common interface for closely related classes, it can also be considered a sort of inheritance abuse. The Category of Change Preventers refers to code structures that hinder modification of the software. These categories include Divergent Change and Shotgun Surgery. The crucial point is that the classes and prospective modifications must have a one-to-one connection. Category of dispensables are Lazy Class, Data Class, Duplicate Code, and Speculative Generality. These code smells denote something that should be deleted from the code. Classes that are not contributing enough must be deleted or their responsibilities enhanced. Category of Encapsulators are the Message chains and Middle Man. The fragrances in this category are opposites, which means that lowering one will cause the other to grow. Encapsulators deal with the objects, data, or operations that are accessed. Category of couplers which are feature envy and Inappropriate Intimacy. Both code smells indicate strong coupling, which is contrary to the object-oriented design principles. Of course, we might argue that these odours belong in the Object-Orientation Abusers category, but since they both focus solely on coupling. It appears obvious that the presence of some fragrances would correlate favorably with the presence of others, while others would correlate negatively. We identified negative connections only with the Primitive Obsession fragrance (Mika Mäntylä, 2003) in our small sample research, which had the greatest (r > 0.575) and most significant (p < 0.01) associations between the code smell.
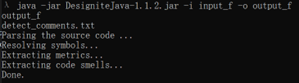
Figure 3.1. Designite Java Process
In the third step of extracting metrics, the thresholds of each code smell are extracted. After extracting metrics, code smells are extracted by using the thresholds and saved to a CSV file record. The process is done with 4 steps.
Designite Java application detects the 10 implementation code smells that do not include comments code smell. We add two code smells which are comments code smell and God Class code smell. Comments code smell can detect the single-line and multiple-line comments in a Java file. To detect comments code smells, we add a regular pattern to match specific types of comments. The regular pattern is shown in the table.
| Single Comments | //[^\r\n]* |
| Multi Comments | /\\*[\\s\\S]*?\\*/ |
| String Comments | \”(?:\\\\.|[^\\\\\”\r\n])*\” |
| Character Comments | ‘(?:\\\\.|[^\\\\’\r\n])+’ |
| Any of comments | [\\s\\S] |
Table3.1.Regular Pattern of Comments Code Smell
The comments code smell did not need have threshold and formula to detect comments. To apply all pattern, we use the java compile function to detect all regular pattern and match to write it to output file.
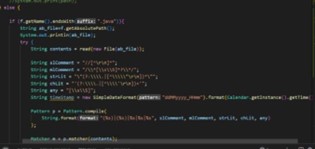
Figure 3.2. Compile Library Function
Compile function is built in java function to compile the pattern of regular pattern. To try read java file first and compare the regular pattern, the true Boolean which match with pattern, it list in text file.
Below is the equation showing the formula and states the thresholds for detecting the God class (GC).
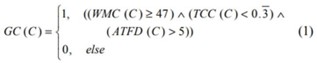
Figure3.3. God Class Thresholds Formula
WMC is the weight method count which sum of the cyclomatic complexity of all methods in class. TCC is the relative number of directly connected to methods in class. ATFD is the accessed to foreign data which the number of attributes of foreign classes or via the accessor methods.
To calculate the tight class cohesion which formula of below:
TCC= NDC/NP
NP is the maximum number for possible connections which N is numbers of methods. The number of methods is calculated as the equation of N * (N – 1). The NDC denotes the number of direct connections, which corresponds to the number of edges in the connection graph. A pair of public methods shares an attribute directly if both methods reference the attribute and transitively if one of the two methods does not reference the attribute but directly or transitively calls a method that does. The open-source code of Designite Java application is a command-based line. To run the application using command to debug whole application. After debugging, we need to click the output to review results.
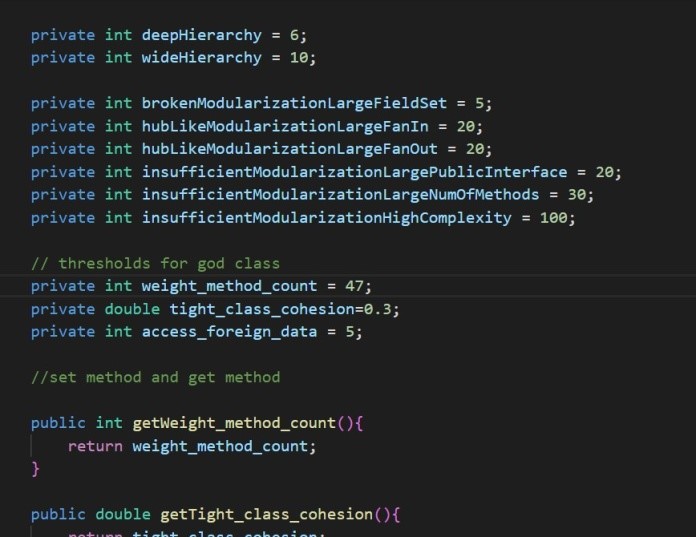
Figure 3.4. Threshold God Class
The threshold for God Class defined in threshold class and it call the function getter and setter for weight method count, tight class cohesion and access foreign data.
Figure3.5. Compare Number of God Class
The number of weight method count, tight class cohesion, and access foreign data compare the threshold. The number is exceeding the threshold, it counts as God Class categories.
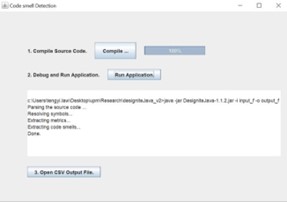
Figure 3.6. Graphic User Interface Code Detection
The graphics user interface shows the steps to click button from steps 1 to 3. First step to compile applications. Compile program to install and build jar application. The progress bar shows the completed of debug applications. Step 2 is run application and show the process for extracting code smells. The done message show completed process after parsing source code, resolving symbols, extracting metrics, and extracting code smells. Last step, we did not need to open output result in folder. The click button of open CSV file will open file to show implementation code smells.
RESULTS
After running the application, the comments code smell detected and saved the information in text file format.
The detection of comments code smell detects single and multiline of comments in Java file.
The output of detection God Class code smell save in CSV file format. The detection of code smell detects line by line of code which list the method, package, and the class of java.
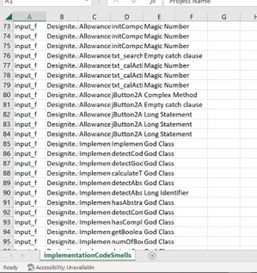
Figure 5.2. God Class Code Smell Output
Besides that God class code smell, the other code smell is detected and recorded.
ANALSYSIS
To evaluate the effectiveness of detection of God Class, we use the open-source project version. Below shows the list of open-source project with version and the number of God class detect with existing detection tool.
Each project was assigned two versions: the target version and the previous version (Khalid Alkharabsheh, 2022). The table’s last column displays the number of classes added to or removed from the previous version of the software projects. This number may be used to show code improvement by deleting classes or separating complicated or huge classes (God Class) into two or more classes, hence reducing the overall number of classes.
| Project Name | Version | Number of God Class Detected |
| Angry IP Scanner | 3.5 | 4 |
| Apeiron | 2.94 | 9 |
| Check style | 8.0.0 | 9 |
| Digi Extractor | 2.5.2 | 36 |
| Free mind | 1.1.0 | 62 |
Table 6.1 Latest Version of Project Source Code.
We use the same version of open-source to test the prototype of code smell detection to detect the number of God class.
The data has been collected to test the hypothesis as listed in table.
The evaluation is shown in the table below, with the negative numbers representing distinct numbers detected on the God class. The existing detection technique can only detect the class, but prototyping detection can identify the god class. The difference in number is derived by subtracting the prototype detection tools from the existing detection tools. Negative values indicate that the God class has been detected. To calculate the effectiveness, divide the protype detection number by the existing detection number plus the prototype detection.
As an example, (1/5) *100 equals 20%. The rest of the class is at 80 percent. 20 percent is the detection of god class, and thus demonstrates the usefulness of scanning the complexity of the Java source code file.
| Project Name | Angry IP Scanner | Apeiron | Check style | Digi Extractor | Free mind |
| Existing Detection Tools | 4 | 9 | 9 | 36 | 62 |
| Prototype Detection Tools | 1 | 2 | 46 | 3 | 58 |
| Different | -3 | -7 | 37 | -33 | -4 |
Table 6.3 Different number of God Class Detection
The paired-sample t-test, also known as the dependent sample t-test, is a statistical process used to determine if the mean difference between two sets of data is zero.
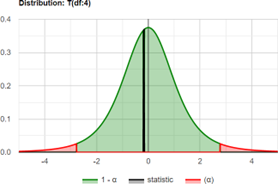
Figure 6.1. Distribution of Two Tails
The p-value equals 0.867, (P (x≤-0.1785) = 0.4335). The larger the p-value the more it supports H0 and it show the high percentage. Since the p-value >α, H0 cannot be rejected.
The paired sample t-test, also known as the dependent sample t-test, is a statistical process used to determine if the mean difference between two sets of data is zero. The p-value equals 0.867, (P(x≤-0.1785) = 0.4335). The larger the p-value the more it supports H0 and it show the high percentage. Since the p-value > α, H0 cannot be rejected.
CONCLUSION AND DISCUSSION
The prototype detection application did not cover all 22 code smells, only 11 of them. The output contains a list of method names, class names, and code smell. The goal is to detect the God class code smell and classify the number of God classes using a machine learning algorithm. Aside from the God class code smell, the comments code smell is included, as is the use of the pattern to discover multiline and single comments. The comments code smell is saved as a text file, while the God class code smell is saved as a csv file.
After running and debugging the application, the information saved in the csv file is overwritten. The prototype application improved command line-based applications by adding a graphical user interface. The limitation is this prototype application only can detect java file or java source code and this application build in java platform. The open-source project code compares existing detection tools and prototype detection tools to the most recent version. Because the runtime is longer and stuck to detect a large number of files and directories, the open-source project code is downloaded from source forge and GitHub repository and input into prototype detection tools one by one.
We comparison with existing approaches to code smell detection for highlighting the strengths and weaknesses.
Existing Approach:
Strengths:
- Can detect a large number of code smells in a file, providing comprehensive coverage.
- Faster runtime, presumably due to simpler detection methods.
Weaknesses:
- Detection accuracy is lacking, potentially leading to false positives or negatives.
- Only shows the numbers of code smells without providing detailed information about the classes affected.
Current Approach (With Classifiers Algorithm):
Strengths:
- Can detect code smells at both the directory and file levels, offering a broader perspective on code quality.
- Provides detailed information, including class names and the number of code smells, in a CSV file, aiding in further analysis.
Weaknesses:
- Longer runtime compared to the existing approach, likely due to the file and directory.
The file should include the java source code, which has the extension java file. To build the code, it should look for duplicate classes in another java file. Because it can detect the god class in many files and duplicate the class, hence increasing the number of detections.
The major aim is to develop code smell detection application prototype to evaluate the effectiveness of detection God Class. The hypothesis testing as below:
H0: UExisting – Uprototype =0
Ha: UExisting – Uprototype ≠0
As the results show the p-value equals 0.867, (P(x ≤ -0.1785) = 0.4335). The larger the p-value the more it supports null hypothesis and it show the high percentage. Conclusion that the existing and prototype detection tools are equal effectiveness and also show that strong evidence that cannot reject null hypothesis.
REFERENCES
- Aliamaan, A.A.(2021).Code smell detection using feature selection and stacking ensemble: An empirical investigation. Information and Software Technology.
- Apostolos Ampatzogloua, S. C. (2013). Research state of the art on GoF design patterns: A mapping study. The Journal of Systems and Software.
- Class, I.o. (2018). Khalid Alkharabsheh, Shahed Almobydeen, Yania Crespo, José A. Taboada. International Computer Sciences and Informatics Conference. Amman Arab.
- Detten, M.M. (2010). Reverse engineering with the reclipse tool suite. Proceedings of the 32nd ACM/IEEE International Conference on Software Engineering, 299-300.
- Dongjin Yu, P. Z. (2018). Efficiently detecting structural design pattern in stances based on ordered sequences. Journal of Systems and Software, 35-56.
- F.A, F. M. (2016). Comparing and experimenting matching learning techniques forced smell detection. Empir. Sofw. Eng, 1143-1191.
- Fowler, M. (1999). Refactoring: Improving the Design of existing Code. Addision-Wesley.
- Fowler, M. (2019). Refactoring: Improving the Design of Existing code. Addison-Wesley.
- Fowler, M. a. (2000). “Bad Smells in Code”, Refactoring: Improving the Design of Existing Code. Addison-Wesley. Guggulothu, T. &. (2020). Code smell detection using multi-label classification approach. Software quality journal, 1063-1086.
- Guilherme Lacerda, F.P. (2020). Code smells and refactoring: A tertiary systematic review of challenges and observations. The Journal of Systems and Software.
- Khalid Alkharabsheh, S. A. (2022). Prioritization of god class design smell: Amulti-criteria based approach. Journal of King Saud University–Computer and Information Sciences, 9332-9342.
- Lincke,R.(2007).CompendiumofSoftwareQualityStandardsandMetrics-Version1.0. IEEEStd1061-1992.
- M.Fowler,K.B.(1999).Refactoring: Improving the Design of Existing Code Reading. MA, USA: Addison Wesley.
- Mantyla M, V. J. (2004). Bad smells- humans as code critics. 20th IEEE International conference on Software Maintenance,(pp. 399–408).
- Martin Fowler, K. B. (2002). Refactoring: Improving the. Addison-Wesley Professional.
- Mika Mäntylä, J. V. (2003). A Taxonomy and an Initial Empirical Study of Bad Smells in Code. Proceedings of the International Conference on Software Maintenance, 1063-6773.
- Moha, N. (2007). Decor: A tool for detection of design defect.
- Ra’ul Marticorena, C.L. (2005). Parallel Inheritance Hierarchy: Detection from a static view of the system. 6th international workshop on object oriented reengineering. van Oort, B.C. (2021). The prevalence of code smells in machine learning projects. IEEE/ACMI st work shop on AI Engineering software engineering for AI, 1-8