
Intelligent Model for the Early Detection of Breast Cancer Using Fine Needle Aspiration of Breast Mass.
- Gabriel James
- Anietie Ekong
- Henry Odikwa
- 348-359
- Apr 16, 2024
- Health
Intelligent Model for the Early Detection of Breast Cancer Using Fine Needle Aspiration of Breast Mass.
Gabriel James1, Anietie Ekong2, Henry Odikwa3
1Department of Computing, Topfaith University, Mkpatak, Nigeria
2Department of Computer Science, AkwaIbom State University, Nigeria
3Department of Computer Science, Abia State University, Uturu, Nigeria
DOI: https://doi.org/10.51584/IJRIAS.2024.90332
Received:18 March 2024; Accepted: 26 March 2024; Published: 16 April 2024
ABSTRACT
Breast cancer is a type of cancer that forms in the cells of the breasts. It can occur in both men and women, but it is far more common in women with an increase likelihood of development caused by some risk factors like age, family history, gene mutations, hormonal factors, and exposure to estrogen. There are several essential methods for early diagnostic and detection, like regular breast self-examinations, clinical breast examination mammograms, etc. Breast cancer detection faces several challenges that span various stages from screening to diagnosis. It is in the light of these, that the drive to overcome these challenges faced by patients and medical experts to get timely diagnosis or detection of breast cancer that motivated this research. The work aims at developing an intelligent-based system for the early detection of breast cancer driven by machine learning algorithm using features obtained from a digitized image of the Fine Needle Aspiration (FNA) of breast mass. The Machine learning algorithm used was the Support Vector Machine (SVM) and was apply to the Breast Cancer dataset. Additionally, feature selection and a neural network model was applied to improve the performance of the system. This work demonstrates that SVM algorithm can be used to enhance the early detection of breast cancer. Compared with the 92% accuracy of mammography, this machine learning model achieved a higher accuracy of around 98.18% for breast cancer detection and diagnosis based on the dataset that was used.
Keywords: Breast Cancer, Medical Diagnostic System, Intelligent Systems, Machine Learning, clinical decision support system, Deep Learning, Support Vector Machine, diagnoses, classification
INTRODUCTION
It is important to note that cancer mortality rates can vary widely depending on the type of cancer, the stage at diagnosis, treatment effectiveness, and other factors. Additionally, cancer mortality rates are often reported as age-standardized rates, which account for differences in age distribution among populations [1][2][3]. It is worthy to note that the major reason for high fatalities in cancer patients is due to late diagnoses. This also result in high cost as the treatment seems to be more costly in late sage presentations.
Breast cancer has risk factors and the knowledge of such risk factors plays a crucial role in its early detection [4]. The search for quick detection and solution of tumor is almost as long as humans have suffered from this ailment. The problem in the treatment and early management of cancer is in diagnosing it when the condition is almost irreversible. It has to be stressed that a large percentage of patients who die from breast cancer are due to late, wrong and incompetent diagnosis or detection.
Each year, more people die of breast cancer than of colon, lung, and prostate cancers combined (ACS online, 2015). Breast cancer is caused by uncontrollable irregular growth of cells in breast tissue. Breast tissue abnormalities that are roughly spherical with round opacity and a diameter of up to approximately 30mm are known as breast nodules. The diagnose and/or detection of cancer, require enhanced image processing and segmentation. According to Simon, et. al. [5], the task of image processing and segmentation is highly susceptible to human errors. These and many other reasons make manual classification results to have very poor outcomes and remarkably increasing the workload for radiologists [5].
Hospital has multiple class of patients who follow different treatment routes. Despite scarce resources and low budgetary provision for healthcare, especially in developing countries, patients are increasingly demanding for better services. Breast cancer patients are not excluded hence the need for timeous and effective solutions to lessen the burden on patience [6].
Application of technology has improved the processes of medical diagnosis especially in the area of detection of cancerous cells, but there are still various challenges which bring about the need to apply more modern and improved approach, particularly Machine learning, to hasten the diagnostic and detection process [7]. According to James et al [2], Machine learning (ML) is a subset of artificial intelligence (AI) that focuses on developing systems that can learn and improve from experience without being explicitly programmed. The core idea is to enable computers to learn patterns and make decisions or predictions based on data. Machine learning continues to evolve with ongoing research, and its applications span various industries, contributing to advancements in technology and problem-solving. It is predicated on the notion that computers, like people, can learn from experience and can analyze and understand data, identify patterns, and enhance their performance on a task. To generalize from experience is one of a learner’s main goals [1]. The learning algorithm must develop a comprehensive model of the space of occurrences that will allow it to make sufficiently accurate predictions in new situations. To enhance the adequate application of machine learning, the use of a competent machine learning algorithm is inevitable. There are various machine learning algorithms, each designed for specific tasks and scenarios. Machine learning algorithms are categorized as supervised, unsupervised, semi-supervised and reinforcement learning. One example is the support vector machine (SVM), which is a supervised learning algorithm that can also be used for classification and regression problems and is employed in this research.
The essence of applying the SVM machine learning techniques is to build this model is in its ability to cluster symptoms and analyze breast images features reports into similar categories. Fine-needle aspiration (FNA) is an approach in which a needle and syringe are used to obtain a tissue or fluid sample from a suspicious mass in the body and in this case, tissue from the breast. It is used by healthcare providers to spot abnormal tissue in the body. The focus of this work is to develop and subsequently implement an intelligent-based image processing framework for early detection of breast cancer using support vector machine algorithm applied on a dataset of features obtained from a digitized image of the Fine Needle Aspiration (FNA) of breast mass.
Review of Machine Learning and Detection of Breast Cancer
In most developed nation, the incidence of breast cancer has grown by 47% over the last ten years and is steadily rising and becoming more prevalent in younger people [4][8]. Hormones, family history, marital status, and history of having children are all factors in the pathogenesis of breast cancer [5]. Breast cancer has some latent features that make them more difficult to diagnose at early stages than later [9][10]. Three techniques are currently used as the foundation for the primary diagnosis of breast cancer: puncture cytology [5], ultrasound scan [11], and mammography X-ray [12]. Early detection of breast cancer improves prognosis and increases the likelihood of cure. As a result, routine screening and early diagnosis are crucial for both the prevention, early diagnoses and proper management of breast cancer cases.
Machine learning (ML) techniques have been effectively applied to the diagnosis of cancer [13][14]. Microscopic examination of cell morphology reveals some degree of distinction between breast cancer cells and features of healthy and normal cells [15]. The findings offers a conceptual basis for additional studies. Since several predictive modeling techniques are now utilized for classifying breast cancer cells, there is need to choose the right ML algorithm because every ML learning algorithm has its own specializations.
Shen et al. [14] used the XGBoost model to predict and categorize breast cancer; recall was 95.83% and accuracy was 97.86%. Deng et al. [16] used the XGBoost algorithm to classify and predict breast cancer with an accuracy of 0.96 and a recall of 0.97. Deng et al. [16] employed many machine learning models to detect breast cancer. The algorithms that produced the best F1-scores, 96%, 95%, 90%, and 98%, respectively, were logistic regression, random forest, K-nearest neighbor, and decision tree. Using multilayer perceptron (MLP), K-nearest neighbor (KNN), genetic algorithm (GP), and random forest (RF), Deng et al. [14] categorized breast cancer cells into benign and malignant categories. The experimental findings showed that RF was the best classifier, having the maximum classification accuracy of 96.24%.
Using machine learning, deep learning, and hybrid machine learning approaches on a variety of datasets, Rahul-Kumar et al. [17] investigate the probability of breast cancer presence. The datasets utilized were databases on breast cancer based in Wisconsin as well as mammography imaging datasets. That study led to the discovery of the ideal breast cancer diagnosis model. Nevertheless, having enough data available is one of the main challenges of applying ML algorithms. Various techniques for feature extraction, including PCA, auto encoders, and MLP, were used to select attributes, clean, convert, and eliminate missing data from datasets. Additionally, it is said that although Artificial Neural Network (ANN)s can be used for prediction, their limited number of layers and neurons prevents them from yielding accurate findings.
A machine learning classification technique for breast cancer diagnosis was proposed by Omondiagbe et al. [18]. They emphasized the necessity of computer-aided detection (CAD) systems that employ a machine learning methodology in order to offer precise breast cancer diagnosis. Early detection of breast cancer can be aided by these CAD systems. Through the use of the Wisconsin Diagnostic Breast Cancer (WDBC) Dataset, their work was able to investigate Artificial Neural Networks, Naïve Bayes, and Support Vector Machines (using radial basis kernel). By first employing linear discriminant analysis (LDA) to lower the high dimensionality of the features and then using Support Vector Machine to the newly reduced feature dataset, they were able to establish a hybrid strategy for the diagnosis of breast cancer. With their method, they were able to achieve 98.82% accuracy, 98.41% sensitivity, 99.07% specificity, and 0.9994 area under the receiver operating characteristic curve. Their work classified aggressive and benign tumors by analyzing the WDBC dataset using three well-known ML algorithms and dimensionality reduction techniques. The research study demonstrates that the choice of ML classification technique affects classification performance. SVM-LDA and NN-LDA outperform the other ML classifier models, according to simulation results. However, due to NN-LDA’s greater computation time, SVM-LDA is preferred over it. Results using this selected strategy over the validation dataset were positive and encouraging. With a sensitivity of 98.41%, specificity of 99.07%, area under the receiver operating characteristic curve of 0.9994, and classification accuracy of 98.82%, these results were achieved. Their research demonstrated how machine learning techniques, such as feature extraction and selection, can enhance the diagnosis of both benign and malignant cancers. They came to the conclusion that improved methods for medical diagnosis can be achieved by combining major dimensionality reduction methods with machine learning classification techniques. Combining the benefits of dimensionality reduction with the ML algorithm was the key idea and suggested future research on refining the selected strategy into a potentially useful technique to support physicians in seeking a prompt second opinion when detecting breast cancer.
According to Richard et al. [9], [13], deep learning analysis of radiological images may enhance breast cancer detection accuracy, which could ultimately result in better outcomes. In order to improve diagnostic accuracy and enable personalized medicine, various deep learning algorithms were analyzed. They emphasized the need for large, diverse, and well-annotated images as well as the need for additional clinical data and risk factors, like age, family history, or genetic mutations, to be incorporated into the model in the future. The came to the conclusion that ML can also lessen the necessity for pointless testing and treatment, such as biopsies.
Every relevant study that was examined demonstrated either a poorer accuracy or a low implementability of the models.
METHODS
Principal Components Analysis (PCA)
One of the main problems to human’s health is proper diagnoses and considering the shortage of health personnel experts worldwide, the risk of being wrongly diagnoses is high and chances of survival are high on early diagnoses while some symptoms may be confusing [19][20]. In order to reduce this risk differentia appracoesh were adopted one of which is the PCA.
In order to have an efficient and less number of parameters for the support vector machine’s training process, PCA approach was employed in the feature selection phase to determine the most significant features and their rank in the data set. As a result, Table 1 presents the dataset’s attributes together with its constituent parts and ranking.
Table 1: Feature Selection in Breast Cancer Datasets
| Features | Principal Components | Importance |
| perimeter_worst | PC23 | 0.14235347 |
| radius_worst | PC21 | 0.14233718 |
| area_mean | PC4 | 0.14110473 |
| perimeter_mean | PC3 | 0.14101228 |
| area_worst | PC24 | 0.14081968 |
| radius_mean | PC1 | 0.14075238 |
| compactness_mean | PC6 | 0.13371907 |
| concavity_mean | PC7 | 0.12626808 |
| concave.points_mean | PC8 | 0.1222614 |
| concavity_worst | PC27 | 0.11953866 |
| compactness_se | PC16 | 0.11903009 |
| compactness_worst | PC26 | 0.11887381 |
| area_se | PC14 | 0.11671039 |
| concave.points_worst | PC28 | 0.11337085 |
| radius_se | PC11 | 0.10872599 |
| fractal_dimension_worst | PC30 | 0.10840609 |
| perimeter_se | PC13 | 0.10839163 |
| concave.points_se | PC18 | 0.10712472 |
| concavity_se | PC17 | 0.10690509 |
| fractal_dimension_se | PC20 | 0.09745587 |
| smoothness_mean | PC5 | 0.09645046 |
| fractal_dimension_mean | PC10 | 0.09626849 |
| symmetry_mean | PC9 | 0.09321022 |
| smoothness_worst | PC25 | 0.08671288 |
| symmetry_worst | PC29 | 0.07664416 |
| texture_mean | PC2 | 0.0598851 |
| texture_worst | PC22 | 0.05695838 |
| symmetry_se | PC19 | 0.05331464 |
| smoothness_se | PC15 | 0.04839319 |
| texture_se | PC12 | 0.02765791 |
From table 2 above, we plot the individual features components with their respective importance in figure 1.
![]()
Fig 1: PCA and their importance Rank
Support Vector Machine
In the context of machine learning, support vector machines (SVMs) are a collection of supervised learning techniques that are frequently used for tasks like anomaly detection, prediction, and classification. Unlike previous classification techniques, Support Vector Machines (SVMs) identify a decision boundary that maximizes the distance between the nearest data points of different classes. This decision boundary is referred to as the Maximum Margin Classifier (MMC). A straight line is constructed between two classes in a simple linear SVM classifier, designating predictor variables on one side of the line as belonging to one category and those on the other as belonging to a different category. This suggests that there are a plethora of possible lines to select from. The best line for classifying data points is chosen by the linear SVM algorithm. In particular, it selects the line that optimizes the separation between the closest data points. Thus, SVM was chosen for this study.
Training and Testing
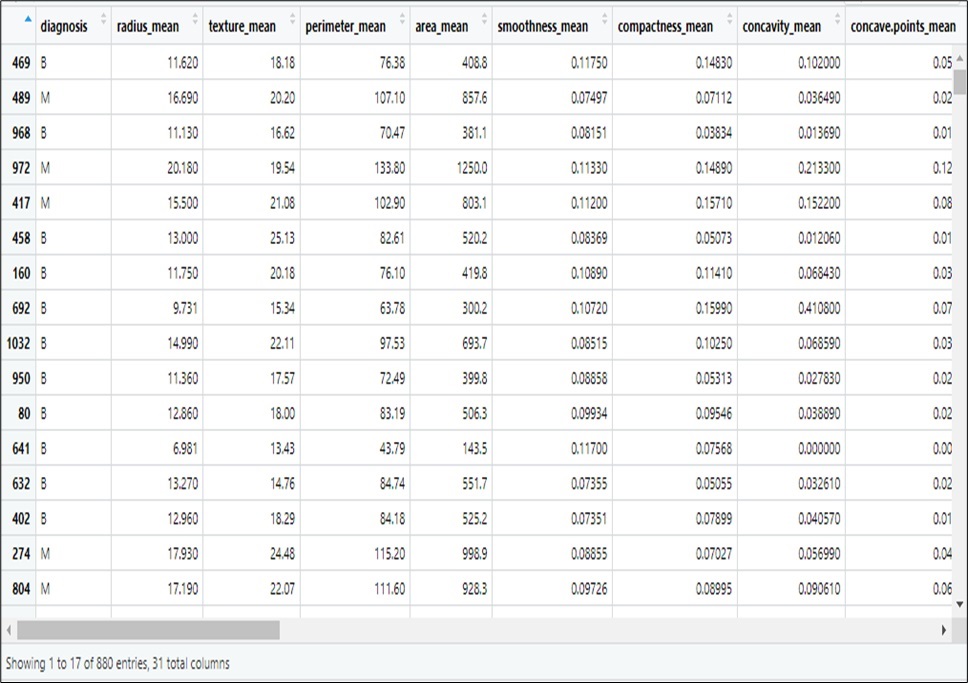
The real dataset used to train the model to execute different tasks is known as the training data set in machine learning. The models learn from this real data as part of the ongoing development process. The aforementioned algorithms present predictions based on data or judgements by building a mathematical model from the input data. The field data set on breast cancer that was collected served as our training set for this investigation. Preprocessing steps were performed on the data to get rid of any redundant and noisy information. For the Machine Learning model, our data was split into training set of 80% and a test set of 20%. The training sets for our model are shown in Table 2.
Table 2: Cross Section of Training Set
Steps used for the Training data on SVM Model
Step 1: Read in the in the CSV data file
Step2: Display the structure of the data
Step 3: Checked whether there are any abnormalities in the data and Perform feature selection using PCA
Step 4: Check for outliners in the data
Step5: Convert the diagnosis column to a factored variable
Step 6: Create a two-way factor table for our severity index
Step 7: Split the data in the ratio of 80:20 % for training and test sets
Step 8: Train SVM model with the training set as split in step 7.
Step 9: Supply the test data into the model for Classification
Step10: Supply the train data into the model for Classification
Step11: Determine the accuracy of the model using the confusion matrix
Step 12: Check the percentage accuracy from our confusion matrix
Step 13: Select the high-ranking features and used for model deployment.
Step 14: Deploy a classification interface.
The system architecture is presented in figure 2:
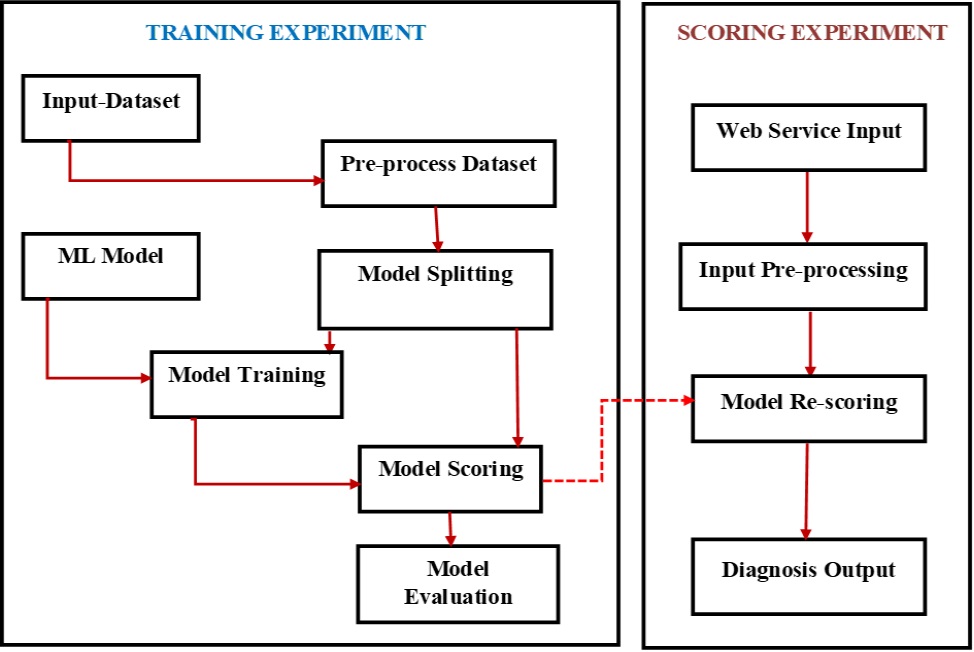
Fig. 2: System Architecture
RESULTS AND DISCUSSION
A Support vector machine to classify was adapted. Consequently, before using our dataset in the SVM model we explore the structure of our data set with all parameters. Figure 3 shows a schematic of the structure of used dataset.
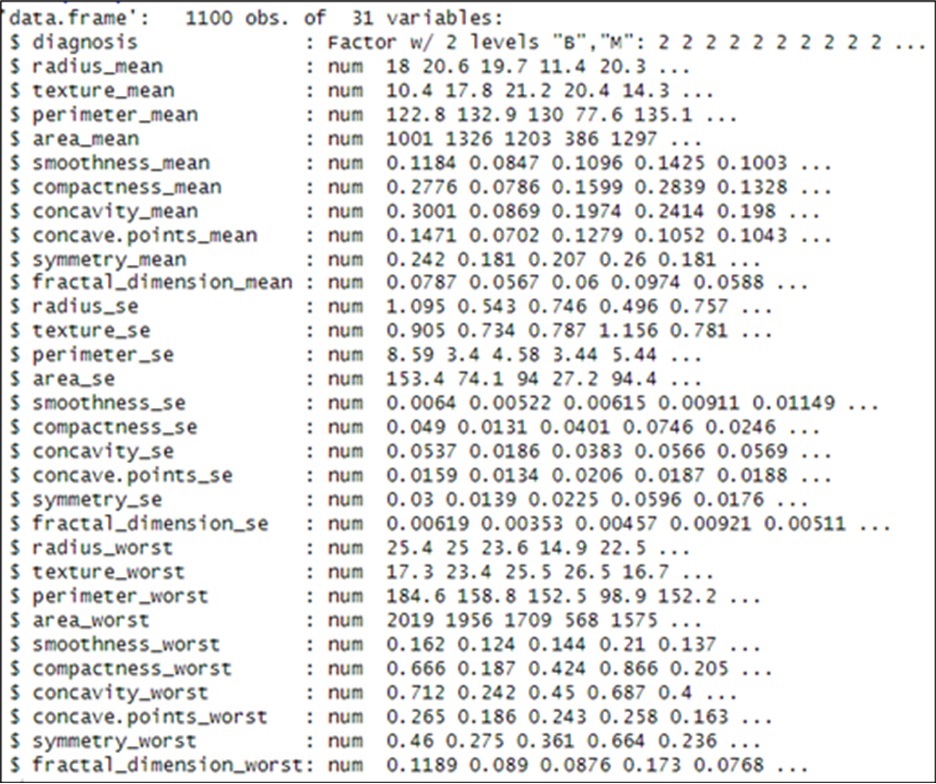
Fig 3: Structure of our SVM data frame
The dataset is fed into SVM in order to produce a which will be used for classification and the result is depicted in figure 4.
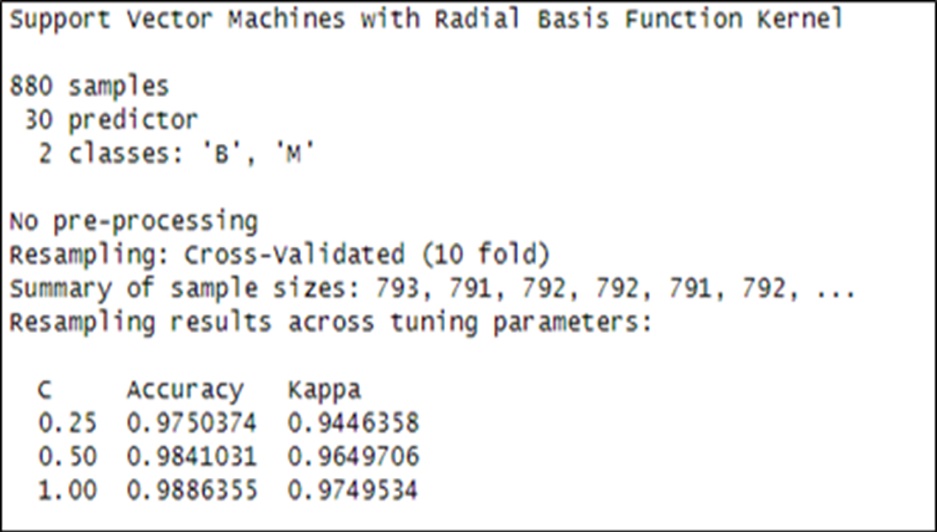
Fig 4: SVM Build Model Result
Furthermore, we present the cross validated accuracy result with 10 cross validation and it associated cost tuning parameter based on the SVM model. This is depicted in figure 5.
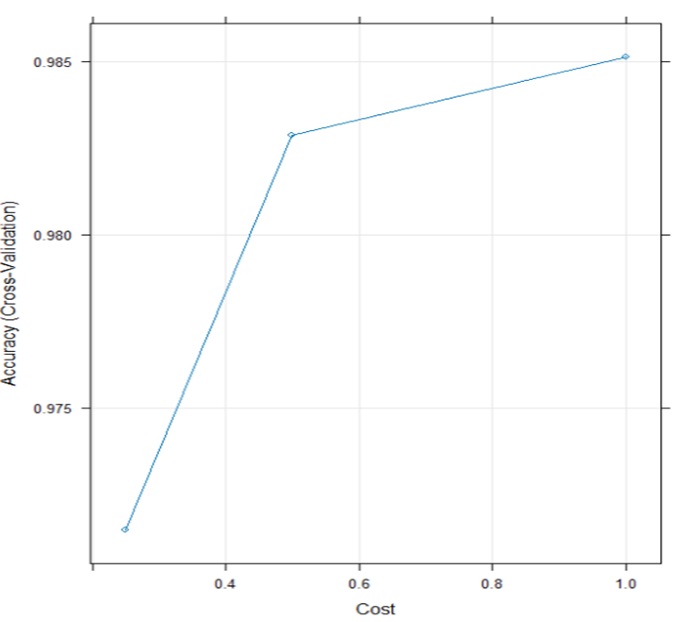
Fig 5. cross validated result
Furthermore, we present the accuracy based on the confusion matrix in figure 6.
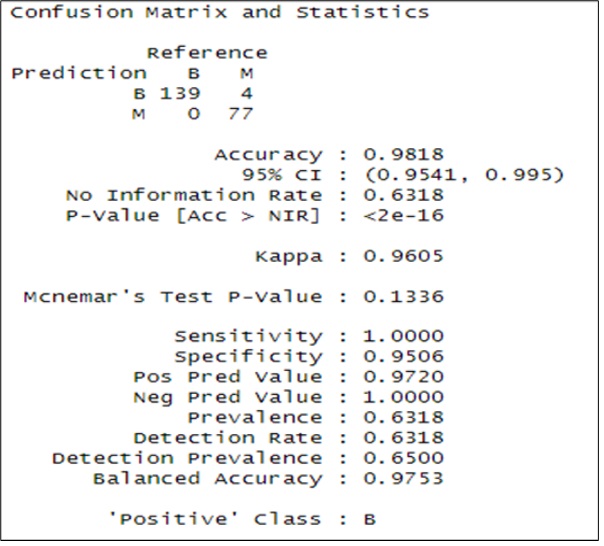
Fig 6: Confusion Matrix and Statistics Result
From the confusion matrix’s we calculate the following performance measure in order to give and extended evaluation of the SVM model result which is presented in table 3.
Table 3: Performance Measure of SVM model using 10 cross validations
| Metric | Value |
| Precision | 0.972028 |
| Recall | 1 |
| F1 Score | 0.9858156 |
| Support | 77 |
The user interface developed from our model is as presented in figure 7.
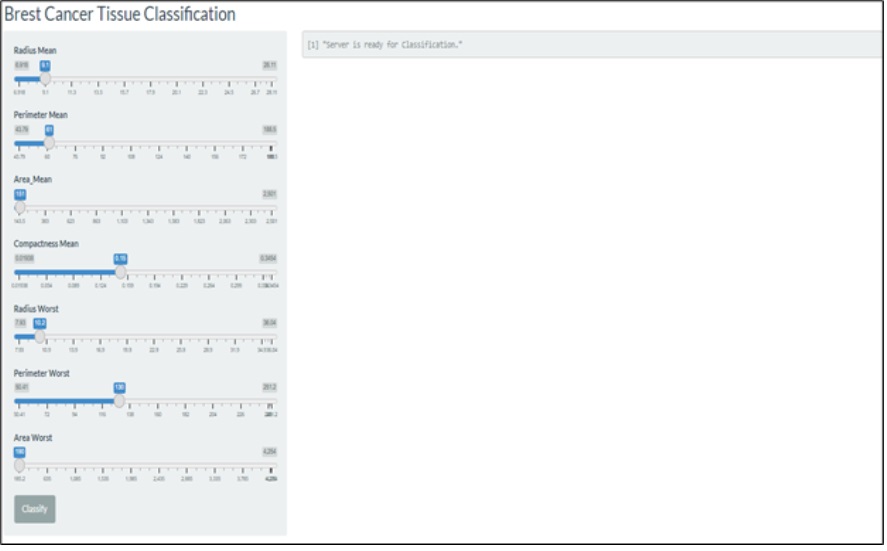
Fig. 7: Interface deployment
With an accuracy of 98.18% and a confidence interval of 95%, the results show how well the model performs. The clinical implications of the results are enormous. For instance, cases of breasts cancer can easily be detected using this intelligent model. This can potentially impact patient’s care in various ways which include but not limited to; early commencement of treatment, early advice to patients on necessary changes in lifestyles that could have otherwise exacerbated their condition, if it remained undiagnosed, and clearing doubts of patients with suspicious cases. More so, the process(es) involving a series of tasks performed by various people within and between health environments to deliver the necessary care to breast cancer patients will be greatly improved. This will give a better diagnostic certainty, which is a precursor to other necessary processes toward enhanced healthcare delivery for proper management or complete eradication of cancerous cells, all geared towards the betterment of the conditions of breast cancer patients.
CONCLUSION
Breast cancer is one of the most common cancer and is causing a huge number of deaths worldwide. The high incidence and mortality is due lack of proper and early diagnose and considerably low diagnostic accuracy of diagnosis. Despite attempts to proffer solutions to diagnostic problems, the efforts have not gone far enough to address the issues of delayed, inaccurate and sometimes outrightly false diagnoses. It is as a result of this that an attempt to use machine learning model to help increase accuracy of the diagnosis of breast cancer using set of features obtained from a digitized image of the Fine Needle Aspiration (FNA) of a breast mass from a patient. We present a diagnosis model using the Support vector machine, a machine Learning algorithm that is good in classification. In order to improve the performance, principal component analysis method was used in the feature selection process in order to identify the most important features and the rank in the dataset in order to have an effective and reduced number of parameters for the training process on the support vector machine. Additionally, neural network was used for feature selection to improve the performance of the system.
And an accuracy of 98.18 % was obtained on our dataset higher that that obtained from mammography and other approaches demonstrating the unbeatable power of machine learning models in the diagnoses of breast cancer.
REFERENCES
- G. James, E. G. Chukwu, and P. O. Ekwe, “Design of an Intelligent based System for the Diagnosis of Lung Cancer,” Int. J. Innov. Sci. Res. Technol., vol. 8, no. 6, pp. 791–796, 2023.
- G. James, A.E. Okpako, and J.N. Ndunagu, “Fuzzy cluster means algorithm for the diagnosis of confusable disease,” vol. 23, no. 1, Mar. 2017, [Online]. Available: https://www.ajol.info/index.php/jcsia/article/view/153911
- Umoh, U. A., Umoh, A. A., James, G. G., Oton, U. U., Udoudo, J. J., B.Eng., “Design of Pattern Recognition System for the Diagnosis of Gonorrhea Disease,” International Journal of Scientific & Technology Research, pp. 74–79, Jun. 2012.
- Fotedar, S. Fotedar, P. Thakur, S. Vats, A. Negi, and L. Chanderkant, “Knowledge of breast cancer risk factors and methods for its early detection among the primary health-care workers in Shimla, Himachal Pradesh,” J. Educ. Health Promot., vol. 8, p. 265, 2019, doi: 10.4103/jehp.jehp_234_19.
- S. Simon et al., “Cardiometabolic risk factors and survival after cancer in the Women’s Health Initiative,” Cancer, vol. 127, no. 4, pp. 598–608, Feb. 2021, doi: 10.1002/cncr.33295.
- Imeh J. Umoren, Ubong E. Etuk, Anietie P. Ekong, Kingsley C. Udonyah (2021). Healthcare Logistics Optimization Framework for Efficient Supply Chain Management in Niger Delta Region of Nigeria. International Journal of Advanced Computer Science and Applications,Vol. 12, No. 4, 2021
- AnietieEkong, ImmaculataAttih, Gabriel James and , UnyimeEdet, “Effective Classification of Diabetes Mellitus Using Support Vector Machine Algorithm,” Res. J. Sci. Technol., vol. 4, no. 2, pp. 18–34, Feb. 2024.
- O. Vorontsov and A. N. Averkin, “Comparison Of Different Convolution Neural Network Architectures For The Solution Of The Problem Of Emotion Recognition By Facial Expression,” 2018.
- Adam, K. Dell’Aquila, L. Hodges, T. Maldjian, and T. Q. Duong, “Deep learning applications to breast cancer detection by magnetic resonance imaging: a literature review,” Breast Cancer Res., vol. 25, no. 1, p. 87, Jul. 2023, doi: 10.1186/s13058-023-01687-4.
- F. Pasha, R. H. Mohamed, M. M. Toam, and A. M. Yehia, “Genetic and epigenetic modifications of adiponectin gene: Potential association with breast cancer risk,” J. Gene Med., vol. 21, no. 10, p. e3120, Oct. 2019, doi: 10.1002/jgm.3120.
- Zhong et al., “Contrast-Enhanced Ultrasound-Guided Fine-Needle Aspiration for Sentinel Lymph Node Biopsy in Early-Stage Breast Cancer,” Ultrasound Med. Biol., vol. 44, no. 7, pp. 1371–1378, Jul. 2018, doi: 10.1016/j.ultrasmedbio.2018.03.005.
- Babic, C. Siguan-Bell, M. Hee, and S. C. Lin, “Ocular Gossypiboma: Ultrasound B-Scan Assessment of Retained Surgical Sponge after Ahmed Valve Surgery: A Case Report,” J. Glaucoma, vol. 26, no. 10, pp. e239–e241, Oct. 2017, doi: 10.1097/IJG.0000000000000744.
- Yala et al., “Toward robust mammography-based models for breast cancer risk,” Sci. Transl. Med., vol. 13, no. 578, p. eaba4373, Jan. 2021, doi: 10.1126/scitranslmed.aba4373.
- Chen, N. Wang, X. Du, K. Mei, Y. Zhou, and G. Cai, “Classification Prediction of Breast Cancer Based on Machine Learning,” Comput. Intell. Neurosci., vol. 2023, pp. 1–9, Jan. 2023, doi: 10.1155/2023/6530719.
- Y. Huang et al., “Telemedicine and telementoring in the surgical specialties: A narrative review,” Am. J. Surg., vol. 218, no. 4, pp. 760–766, Oct. 2019, doi: 10.1016/j.amjsurg.2019.07.018.
- Akbulut, I. BalikciCicek, and C. Colak, “Classification of Breast Cancer on the Strength of Potential Risk Factors with Boosting Models: A Public Health Informatics Application,” Med. Bull. Haseki, vol. 60, no. 3, pp. 196–203, Jun. 2022, doi: 10.4274/haseki.galenos.2022.8440.
- Dennetiere, H. Saad, Y. Vernay, P. Rault, C. Martin, and B. Clerc, “Supporting Energy Transition in Transmission Systems: An Operator’s Experience Using Electromagnetic Transient Simulation,” IEEE Power Energy Mag., vol. 17, no. 3, pp. 48–60, May 2019, doi: 10.1109/MPE.2019.2897179.
- A. Omondiagbe, S. Veeramani, and A. S. Sidhu, “Machine Learning Classification Techniques for Breast Cancer Diagnosis,” IOP Conf. Ser. Mater. Sci. Eng., vol. 495, p. 012033, Jun. 2019, doi: 10.1088/1757-899X/495/1/012033.
- Anietie Ekong, Henry Odikwa, Otuekong Ekong 2021. Minimizing Symptom-based Diagnostic Errors Using Weighted Input Variables and Fuzzy Logic Rules in Clinical Decision Support Systems. International Journal of Advanced Trends in Computer Science and Engineering10(3), 1567 – 1575.
- Anietie Ekong, Blessing Ekong , Anthony Edet. Supervised machine learning model for effective classification of patients with covid-19 symptoms based on bayesian belief network Researchers Journal of Science and Technology (2022) 2: 27 – 33