
Mobile Agent Improvement Testing on A Distributed Network Cluster Using Unsorted Metadata with A Distribution and Delocalization Model (DAME)
- Benard Osero
- Elisha Abade
- Stephen Mburu
- 84-100
- Sep 14, 2023
- Computer Science
Mobile Agent Improvement Testing on A Distributed Network Cluster Using Unsorted Metadata with A Distribution and Delocalization Model (DAME)
Benard Osero, Elisha Abade, Stephen Mburu
Department of Computing and Informatics, University of Nairobi, Nairobi, Kenya
DOI: https://doi.org/10.51584/IJRIAS.2023.8810
Received: 03 July 2023; Revised: 11 August 2023; Accepted: 14 August 2023; Published: 10 September 2023
ABSTRACT
There has been growing demand for high performance systems for processing of both structured and unstructured data thus prompting managers and Organizations to find better methods for addressing the data processing needs now and in the future. The trend is projected to increase exponentially, as virtualized and distributed IOT systems are likely to exacerbate the problem as individual nodes will handle large chunks of data; consequently, these organizations are immersing their energies and resources in the research and use of Intelligent tools for data management and analysis which require real time processing, storage and transmission. Our research inspired by the Amidal’s law and Gustafson Barsis law of distribution uses Mobile agent distribution model complimented with map reduce in a virtualized environment to discover the extent to which the distribution of server nodes may improve performance as compared to the centralized server nodes in order to handle large amounts of data that will be produced and transmitted by the individual nodes. The distribution model in our research borrows from the concept of divide and conquer algorithms whose run-time is O (n log n). To test performance improvement, we employed a custom made Simulator called DAME, which has the capability of catching and distributing metadata through its agent based domain controller. Our research indicates that distribution of nodes on a network has a significant performance improvement with throughput increasing by 88 %, Latency decreasing by 23% and Scalability improvement by up to 43 %.
Keywords: Unsorted Metadata, Mobile Agent, Agent Controller, Distributed Network, Map reduce.
INTRODUCTION
Virtualization is a powerful feature that plays a role in the current success of storage arrays. By design, virtualization manages where data is located and controls access to data for users and applications.
Mobile Agent technology is a recent trend that is gaining attention in the field of distributed computing. The mobile agents most common technology applications are in client-server environment [20]. A common issue encountered in the applications of mobile agents, is the choice of the platform to be used; [20, 14] the strength for the use of Mobile agents is their capability of being compiled in any programming language, they not only can move by themselves but also changes their present state and relevant data and therefore, they act on near real time in their current destination host computer. This strength if properly exploited can lead to creation of near real time storage requests and responses.
Mobile Agents, the flow of control actually can dynamically be moved across the network, instead of using the request/response architecture of client/server; which allows for efficiency and optimization at several levels.
Inspired by mobile Agents technology our model meticulously blend Map reduce paradigm in a distributed virtualized environment and Mobile agents in metadata management. Our model is a solution to the current client-server environment [1] which normally is not scalable and flexible. The key advantages are in the use of a customized easy to use distributed network management model, presented as a Simulator with an aim of comparing client/server with mobile agent paradigms in their response times and traffic generated during data transfer [16].
The objective of this research is to evaluate the performance of a centralized distributed Agent based Distributed system model with a distributed/decentralized agent based distributed network environment specifically OSD,enhanced with map-reduce. In order to achieve this objective two pertinent questions will be answered; 1.Does distribution of nodes on a distributed network have any effecct on it’s performance? 2. To what extent does distribution of metadata or nodes on a distributed virtualized environment affect performance?
The client/server model is advantageous because of enabling the removal of the client to other smaller, remote machines, it equally works well for certain applications. However, for a system with centralized server and many clients, experience simple scaling. With multiple servers; the scaling problems increase exponentially because of individual connections with the server. [1]:
- The client reliably needs to connect to its server, by first being authenticated and secured.
- The client assurance of a predictable response from the server.
- It needs good bandwidth for easy copying and transfer across the network.
As the applications grow there is every reason to equally increase the client/server programming rapidly without which it may become an impediment to change.
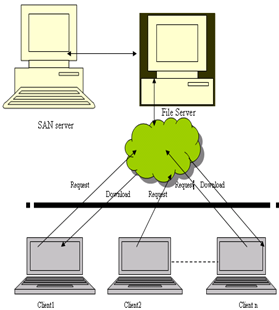
Figure 1. Showing Classical store and forward processes through the file server.
Figure 1 above shows the interaction between the clients and file server over storage area network where the file has to be downloaded to the file server before the client requesting for it. This essentially leads to duplication of resources and decreasing performance.
Mobile agents are a solution to the current client-server environment [1],which normally are not scalable and flexible. The key advantages are in the existence distributed network management systems, are presented [16] as a mathematical model, with an aim of comparing client/server with mobile agent paradigms in their response times and traffic generated around management station
With Mobile Agents, the flow of control actually can dynamically be moved across the network, instead of using the request/response architecture of client/server; which allows for efficiency and optimization at several levels. With Mobile Agents; Servers can also be upgraded, services moved, load balanced, security policy enforced, without interruptions or revisions to the network and clients. [26] describes some of the common agent service as a component to provision user machines or application servers across the whole enterprise. They provide remote deployment capabilities, secure connectivity, and shared machine resources. The Services they offer include:
- Agent manager- It ensures a secure connection between managed endpoints and maintaining the database information.
- Common agent- It acts as common container for all of the subagents to share resources during the management of a system.
- Resource Manager-Together with the subagents they are used for software distribution and software inventory scanning.
RELATED WORK
In their classification model [3] identify Direct attached storage which [18] referred to as store and forward (SAF); in this type of storage the network disks involved have to keep a copy of another redundant disk in the server. Every time a client requests for a file a copy of the file has to be kept before it is forwarded to the client for downloading. [18] further compared DAS and NASD and demonstrated that by keeping a copy of the disk there was a penalty on performance and scalability he further demonstrated an improved security mechanisms using tokenization on these platforms. He concluded that such systems can be improved by use of Object storage management schemes and he proposed further work on mobile agent and mobile code migration on a distributed network.
Network-Attached Secure Disks (NASD), is a Networked object based shared storage system shown [3] in their classification taxonomy, that modifies the interface for the common direct attached storage devices and thus eliminating the server resources required for the movement of data.
In spite of the of OSD’s strengths in as far as metadata handling is concerned, recently there has been an upsurge of storage interactions between the client and the server that OSDs have not been able to address. OSDs employ single thread requests and sequential search of metadata, which in effect leads to increased bandwidth and high latencies [19,18, 11, 10, 17, 16].
Although [2] provide a solution to bandwidth issues which occur when the client and server interact, this solution only improves on bandwidth and not latencies. In their solution[10,12] extensively used unsorted blocks of metadata for mapping the metadata to the client, which are not efficient.
Data prefetching methods have also been implemented through predictive prefetching algorithms which employ the relationship graphs which are more efficient [28], but still this solution is only meant for data management and not for metadata management schemes.
To improve on the inefficiencies identified in the current object storage archtectures[16] indicates that Mobile agents can be flexibly configured to be scalable than the current existing communication networks. [22] developed a platform for dynamic arrangement and communication of mobile agents for distributed computers but he didn’t elaborate on the use of the platform for file management and how the files could affect performance and scalability; Although [23] implemented the model for dynamically organizing multiple mobile agents he only analyzed the agent size and the cost implication; which indeed indicated that there was a direct correlation between them.
DAME ARCHTECTURE
The DAME is a parallel mobile agent based data storage architecture which defines an intelligent way of managing a distributed network through the use of mobile agents, the agents are controlled by a central controller called the Domain Controller that keeps track of all the mobile agents in its registry.
Unlike the OSD system discussed by [19,18, 11, 10, 17, 9]. this intelligent network model has the capability of minimizing latencies by localizing data in its local cache for subsequent client access.
Figure 2 below distinguish key architectural features of the agent based design (DAME) which includes the following functionalities:
- Client-It is an important aspect of this distributed architecture; It is responsible for requesting for the files and then allowing the clients to view the files through the console or preferred browser interface.
- Main Agent -It is responsible for migrating sorted metadata values from the virtual resource server to the client side.
- Domain Controller– Manages the local switching of clients and keeps a registry of the requested and served metadata requests for each client, it also caches the requests for future access.
- Virtual Server (VS)-It contains the logical implementation of the switching of networks to enable the clients access the metadata. It is also responsible for the authentication of the clients by providing a tokenization mechanism whose capabilities are stored in the database and later mapped onto the storage to allow clients download files.
- Storage Area Network (SAN) – It is responsible physical files storage it is implemented as a storage container that has a global IP address to identify the container; included is also the port number and individual internal IP address to identify each internal individual container.
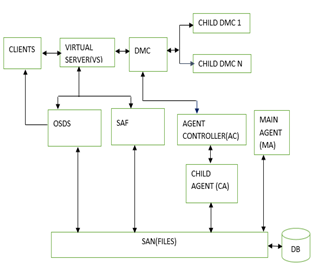
Figure 2. DAME Architecture.
Dame Parallel Computation
DAME partitions the computation workload between the client and Agent Based OSDs as per the capability of the available in the client and agent based OSD nodes. DAME ensures that there is proper system utilization and network workload in both client and SAN. It acquires this information from the DMC which controls the generated child processes. Whenever a READ/WRITE request arrives at the DMC, it issues authentication for every child process generated.
The general operation of the DAME simulator follows a well-defined algorithm to partition the workloads. The workloads, number of possible file requests per SAN, are also classified based on Google Cluster Trace (GCT) to classify Tasks into: DATASET (S=Small, M=MEDIUM, L=Large), [4, 24]; small (1-500), medium (501-1000) and large (1001->=10000). Our experiment involved three files selected randomly from SAN 1,2 and 3 respectively, with the corresponding size in bytes selected from table 1 below. SAN1 = 234 Bytes, SAN 2= 9 Bytes and SAN 3= 18432 Bytes.
| Low | Medium | Large | Very Large | |
| 0 bytes | SMALL | MEDIUM | LARGE |
Max bytes
Figure 3. SAN workload partitions
After the SANs were fully running we loaded files measured in Bytes to each of our three SAN containers.
The files (Bytes) were first classified as shown in figure. 3 above. For Performance optimization and measurement, we define three parameters: LOW, MEDIUM and LARGE, as shown in Figure. 3 above. If the WORKLOAD weight is lower than LOW, the DAME workload is not heavy. If the WORKLOAD is between LOW and HIGH, the CPU workload is MEDIUM. If the WORKLOAD is higher than LARGE, the CPU workload is very LARGE.
For network utilization, we first set parameters for calculating the network performance and utilization three parameters were used (Throughput, Latency and Scalability) to measure the performance DAME ENGINE:
- Throughput is influenced by latency whereby excessive latency creates bottlenecks that prevent data flow calculate_throughput(latency, file_size_in_bytes): totalFileSizeMb = (file_size_in_bytes / (1024 ** 2)) * 8 throughput = totalFileSizeMb / latency
- Latency is defined as Propagation delay+ Serialization time calculate_latency(start_time, time_taken, prev_end_time): propagation_delay = (start_time – prev_end_time) * 1000 serialization_delay = time_taken latency = propagation_delay + serialization delay
- Scalability is the ability of the sysytem to withstand increased loads is presented as data chunks represented in a graph with x:timeTaken & y:totalFileSize over time.
[chunk. length – 1]] (A variable used to determine Scalability over time as load Increase); chunk[chunk.length – 1]]; // const timeTaken = ending_time – starting_time; const timeTaken = ending_time – overall.starting_time; const totalFileSize = metadata.size * chunk.length (Plot graph as x:timeTaken & y:totalFileSize over time).
There were also three SAN containers (SAN 1, SAN2 and SAN 3) as shown in table 1.The file sizes were capped at 30000 bytes, because in the course of our experiments we realized that files beyond this limit become a performance impedement especially with multiple threads/several machines running simultaneously.
Table 1. Files Sizes in The San Container in Bytes.
| #NO | SAN 1 | SAN 2 | SAN 3 |
| 1 | 1 | 1 | 1 |
| 2 | 9 | 6 | 1 |
| 3 | 12 | 6 | 1 |
| 4 | 15 | 9 | 6 |
| 5 | 22 | 20 | 9 |
| 6 | 234 | 171 | 9 |
| 7 | 331 | 684 | 12 |
| 8 | 342 | 993 | 15 |
| 9 | 855 | 11264 | 20 |
| 10 | 9467 | 11410 | 22 |
| 11 | 9467 | 11410 | 22 |
| 12 | 12288 | 15360 | 513 |
| 13 | 15360 | 18386 | 662 |
| 14 | 18432 | 18386 | 10240 |
| 15 | 20480 | 19456 | 12288 |
| 16 | 20983 | 20916 | 18432 |
| 17 | 40685 | 25600 | 18463 |
The workloads request classifications for each client requests were classified and represented in the table shown below. The metadata scheme is either sorted or unsorted. Our experiments only focused on the unsorted metadata.
Table 2. Workload Requests Classifications for Object Based and Agent Based Metadata Based Models.
| Workload Type (NO. of REQUESTS) | Base No of Request(s) | Max No. of requests | Metadata scheme |
| Small | 1 | 500 | Unsorted |
| Medium | 501 | 5000 | Unsorted |
| Large | 5001 | >=10000 | Unsorted |
Our distribution model has has its support from the theoretical models which support massively parallel environments;in his analysis [15], notes that Parallelization is the splitting of processing work and its distribution across processors and nodes.
The serial part of the computation has got limited scalability – this relationship has been formulated in Amdahl’s Law, [15] as demonstrated in the following functional code:
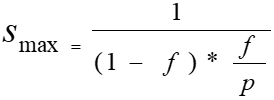
Where f is the portion of the program that is parallelizable, and p be the number of processors (or nodes). S max is the maximal speedup.
From the above expression it can be observed that depending on the code that is parallizable, for a totally parallelizable program f = 1, the speedup is p. However, since in practice, f < 1, the speedup becomes sub linear and is bounded by a constant, which it asymptotically approaches with an increasing number of processors [15].
The relationship defined above generates pessimism regarding the viability of massively parallel systems. But, researchers in parallel computation community started analyzing the usefulness and validity of Amdahl’s law after observing impressive linear speedups in some large applications: Gustafson reported near-linear speedups on 1024-processor hypercube for three practical applications including beam stress analysis, surface wave simulation, and unstable fluid flow. This led to suspecting the nature of Amdahl’s original formulation.
Gustafson argued that Amdahl’s law was inappropriate to support current approaches to massively parallel processing and instead suggested an alternate scaled speedup measure. E. Barsis proposed an improved scaled speedup formula, which is often referred to as Gustafson’s law and stated as follows: if the fraction of time spent by the sequential part on a parallel system is g, then with N processors the scaled speedup is S = g + (1-g) *N, a simple linear relationship which indicates that further that speed can linearly be achieved where the number of machines have been sub-divided from the parent machine. This concept prompted us to investigate the viability of distribution in supporting massively large distributed virtual nodes.
Mobile agent-based Map reduce processing
The Domain controller agent in the DAME architecture supports Map Reduce processing with mobile agents which involves five steps as explained in [23].
Step 1 A Mapper agent corresponds to the master node of the original Map Reduce. The agent makes copies of Worker agents.
Step 2 Each of the Worker agents migrates to one or more data nodes, which locally have the target data.
Step 3 Each of the Worker agents executes its processing at its current data node.
Step 4 After they execute processing, Worker agents migrate to the computer that the Reducer agent is running on with their results.
Step 5 Each Worker agent sends its results to the Reducer agent via local inter-agent communications.
Map reduce has many applications in Data mining models in the Internet of things where huge datasets are kept Figure 4 below shows how the Map and reduce operations work with a join operation [15].
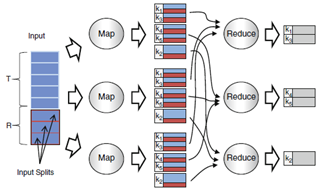
Figure 4. A reduce side join in Map-reduce
The input file requests are entered through the graphical user interface and then the requests are mapped as Key, Value pairs onto the agent controller, the agent controller looks for the metadata in the sorted metadata cluster that is then transported and cached as a single request (in case of multiple similar requests) on the child DMC controller for future client requests to avoid multiple fetch execute cycles from the Parent DMC. This helps minimize multiple redundant transmission of similar files/data on the same channel. The DAME architecture employs a similar mechanism in the file control, transmission and catching.
VIRTUAL ENVIRONMENT SETUP
The DAME Architecture in our research is a three tiered model: The Client side, the Middleware/Operations and Storage (Database and SAN). This virtual environment was designed as a bridged network built on the Docker containers as virtual instances and storing the metadata information in the Redis database. A container is a standard unit of software. The Docker engine was preferred in the design of a simulator because of its capabilities as explained [5]. The Virtual environment set up for our system was carried out as follows:
We installed the Docker Engine by following the Installation instructions found in the installation manual explained in [5]; then inside the Docker engine the agents were designed and incorporated using the SPADE framework within Python, to allow for the metadata sorting and shuffling the map reduce algorithm was used which then allowed for the formation of the corresponding sorted IP addresses Domains for respective client address domains. The Sorted Metadata Domains were then subsequently mapped to a mobile agent which then migrated them to a Domain Controller (DMC), where they were executed henceforth, a client could terminate normally or abnormally in case of an unrecoverable event. A Domain controller had the potential of enforcing the local cache registry where all the client request IDs would be sent to avoid malicious attacks or unauthorised access to data.
To easily answer the research questions posed by the researcher various experiments were then carried out in various phases using the DAME engine in order to test performance improvement of the system (Latencies, throughput) and Scalability as defined in the G-QoSM framework for Network QOS measurement [27] where the Network quality of service metrics are categorized into three broad types: latency, throughput, and availability, which conforms with the RFC 2544 standard established by the Internet Engineering Task Force (IETF) [21].
The DAME agent design followed [26] agent architecture model agent module is divided into four parts as shown in figure 3 above:
- Main Agent (MA).
- Child Agents (CA).
- Agent Controller(AC).
- Domain controller (DMC)
The Main agent (MA) roles include:
- Publishing their location to DMCs
- Receiving a request from DMCs
- Fetching the file metadata from the VS, from the request it receives from DMCs
- Returning the fetched file metadata to the DMCs
- Keeping a cache to store files replicated to them
The Child agents (CA) roles include:
They are a replica of the main process and have to be authenticated via the agent controller sub-module. Once the work of the child agent is completed it terminates normally otherwise it will be terminated by the Main Agent. The only difference between the Main Agent and the Child Agent is that the child agent is controlled by the Agent controller and therefore directly answerable to the Main agent, while the Main agent links with the Domain controller(DMC), where both the Agent controller and Child processes will be cached.
The Agent controller(AC) roles include:
They are responsible for monitoring the child agent behavior and security. It keeps the ID of every child agent and any other information about the agents, it is an instance of the DMC that caches the file information for the mobile agents.
The Domain controller (DMC) roles include:
- Authentication of clients. Acting as a proxy to the VS that authenticates clients.
- Keeping a registry of all the active mobile agents e. allowing the online mobile agents to publish their presence to it.
- Receiving a request from the Client. The request contains a key-value pair of the resource that needs to be retrieved, and number of times the resource should be retrieved.
- Assigning the request received from the client to one of the online mobile agents.
- Receiving the retrieved file metadata from mobile agents, fetching the file resource from its metadata and replicates it to mobile agents, at the same time returning the resource to the requesting client.
Virtual environment interaction design
DAME model was build on a virtual environment based on the Docker contantainer technology; upon successfully installing Docker containers the next step was to initialize the Network objects within Docker for them to communicate with the other remote objects via the REST API. Once Docker Environment was set up then the Docker build command was executed to build an image.
The Docker image was built using a Docker file. Each instruction in the Docker file was added a new “layer” to the image, with layers representing a portion of the images file system that either add or replace the layer below it. The figure 5 below summarizes a general network configuration architecture for the DAME model.
Once the virtual environment has been setup the agent objects also had to be launched together with the Docker daemon. One Advantage that Python Environment provides is an FIPA compliant Agent development model called SPADE(Smart Python Agent Development Environment) [14] whose strengths are explained by [6].The mobile agents in the DAME simulator was designed and implemented using the SPADE framework. The framework is inbuilt in Python Environment and it follows the FIPA framework architecture specifications as outlined in [8, 29] based on the Jabber/XMPP protocols and technology. The SPADE platform was enabled to run on the DAME engine from where our agent objects were spawned. The Agent module and client were run together as one container which contains Port numbers; 8080 and 8000 respectively.

Figure 5. Port Configuration in the DAME engine.
Comparison with other frameworks
This section compares and contrasts DAME platform with the implementation of a few other frameworks that have employed map reduce programming model. It is not fair to compare our platform directly with the other existing frameworks since each is differently implemented and also uses different hardware and software platforms. However, the DAME architecture has many similarities with the work such as Hadoop and MRAM. For instance, they both allow utilization Map reduce, object oriented programing model and although implemented in Java environment and our model is implemented in Python. However, there exist some significant differences, especially in respect to the architecture, task allocation, reliability and system design especially in mobility.
Hadoop architecture consists of a Hadoop Distributed File System (HDFS) and a programming framework Map Reduce. HDFS stores big files across machines in a large cluster. Each file is stored as a sequence of blocks. Each block is sent to three or more machines for fault tolerance.
Hadoop enables distributed, data intensive and parallel applications by dividing big data into smaller data blocks. Hadoop has exhibited several weaknesses as identified by [7]:
- Hadoop Needs high memory and big storage to apply replication technique.
- Hadoop supports allocation of tasks only and do not have strategy to support scheduling of tasks.
- Still single master (Name Node) which requires care.
- Load time is long.
- Vulnerable by Nature: The framework is written almost entirely in Java, one of the most widely used yet controversial programming languages in existence. Java has been heavily exploited by cybercriminals and as a result, implicated in numerous security breaches. For this reason, several experts have suggested dumping it in favor of safer, more efficient alternatives.
- Hadoop distributed file system lacks the ability to efficiently support the random reading of small files because of its high capacity design. Small files are the major problem in HDFS.
- Potential Stability Issues: Still under development and therefore there are several versions that are still emerging and therefore making it difficult to be adopted into research as an authoritative validation tool.
- No Caching: Hadoop is not efficient for caching. In Hadoop, Map Reduce cannot cache the intermediate data in memory for a further requirement which diminishes the performance of Hadoop.
In their research [7] have analyzed the behavior of Hadoop with a mobile architecture called Map Reduce Agent Mobility (MRAM) which showed a better performance over HDFS. They also compared other features as summarized in the table 3 below:
Table 3. Comparison Of Hadoop and Mram
| Factors | Platforms | |
| Hadoop | MRAM | |
| Architecture | Client/Server | Distributed Agent |
| Startup time | Long | Less |
| Performance | Less | Better |
| Reliability | Reliable | More Reliable |
| Algorithm | Map-Reduce | Map-Reduce |
| Mobility | N/A | Support |
| Management Disk | Support | N/A |
| Allocation Tasks | Support | Support |
| Scheduling Tasks | N/A | Support |
| Methodology | Object-Oriented | Object-Oriented |
| Language | Java | Java |
The MRAM framework has several advantages derived from the features of mobile agent and Map Reduce technique. The advantages of MRAM are:
- Support allocation and scheduling tasks.
- Provides fault tolerance and don’t need high memory or big disk to support it.
- Load time for MRAM is less than that of Hadoop.
- Solve single master (centralized node) problem by using features of mobile agent.
- Improve execution time because of no need to huge processing to replication data.
The other limitation of Hadoop is that it uses predefined analytical tools like PIG and HIVE which are much like MySQL for handling mostly structured data sets and therefore limiting its applicability to new and emerging analytical tools for NOSQL like REDIS that employs Map reduce for processing of the unstructured data [25].
Because of the Hadoop framework drawbacks there is need to develop a new framework or modify some Hadoop features to overcome Hadoop limitations and improve its performance and reliability [7].
EVALUATION
Our research used the simulation and model and experimental methodology; we intended to understand performance improvement of a new model that was created after the introduction of the unsorted metadata on a distributed mobile agent based virtualized network.
The Simulator in this research was developed using standard Python APIs for the design of the client and server machines using Sockets and standard Docker Containers running on the Linux OS cluster for file storage virtualization (SAN) and also SHA1 encryption scheme for security.
A client initiates a file request based on the criteria of file classification shown in table 2 and figure 3, once the requests were made the expected time taken for each of the above file request variations was generated as a CSV file sliced and output on the Microsoft Excel Sheet and corresponding charts were generated by the simulator, which were then used to automatically calculate latencies, throughput and scalability (i.e. size of file in bytes against time in ms).
Simulation Setup
The simulation environment was setup and run on Intel(R) Core(TM) i7-3687U CPU speed of 2.60 GHz with Installed RAM of 8.00 GB with a 64-bit operating system, x64-based processor.
Once the environment was setup and the simulator was running then a client first logs into the system using a set password and user name, once authenticated the simulator generates data reports based on the selected method, our analysis was based on unsorted mobile agents with map-reduce (centralized) and then unsorted mobile agents with map-reduce (decentralized). Then the file was selected from the three SANs as per our system set up as shown in table 1 above and finally downloaded. After the simulator was run the various performance reports were generated as outputs as demonstrated in the subsequent section. It is at this point that CSV file sliced and output on the Microsoft Excel Sheet and corresponding charts were generated by the simulator, which were then used to calculate latencies, throughput and scalability (i.e. size of file in bytes against time in ms).
Quantitative research was used to assess and describe the performance improvement of a centralized agent based distributed network with map reduce as compared to a decentralized/distributed agent based storage models.
The centralized Agent based (OSD were compared to the distributed agent based OSD models and their performance was recorded and subsequently analysed in order to address research question; 1.Does distribution of nodes on a distributed network have any effecct on it’s performance? 2. To what extent does distribution of metadata or nodes on a distributed virtualized environment affect performance? It is important to take note that the Simulator has the capabilty of sorting the metadata clusters by using the map reduce algorthm and also an option of not sorting the metadata clusters. Our experiment was based on the unsorted metadata clusters. In future we will analyze the effects of sorting the metadata clusters on performance of the distributed data in handling files (Specifically the structured ones).
After running the simulator for both centralized and distributed agent controls we were able to measure Latency, Throughput and Scalability for 100 and 1000 client requests representing Figures a and b respectively.
Observations
The centralized Agent based (OSD were compared to the distributed agent based OSD models and their performance was recorded and subsequently analysed in both the graphical output and CSV outputs the were tabulated by finding the average of the time taken, throughput and latencies as shown in table 4 below. The figures are represented as: Figure. 6a and 6b representing Latencies, Figure. 7a and 7b representing Throughput and Fig. 8a and 8b representing Latencies. Each of the graphs contains centralized agent control and decentralized agent control mechanism.
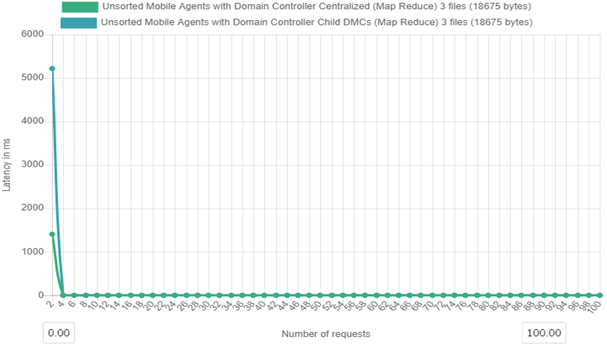
Figure 6a. Latency over time for centralized and distributed mobile agent controllers with 100 client requests
Figure 6a above shows how the distributed cluster is affects latencies by either centralizing or decentralizing the metadata control and nodes. In the experiment there are 100 client requests are made then their latencies are captured from 2 requests up to the 100 requests.
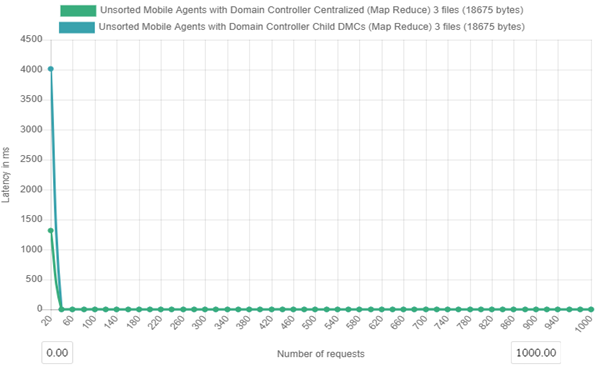
Figure 6b. Latency over time for centralized and distributed mobile agent controllers with 1000 client requests
Figure 6b above shows how the distributed cluster is affects latencies by either centralizing or decentralizing the metadata control and nodes. In the experiment there are 1000 client requests are made then their latencies are captured from 20 requests up to the 1000 requests.
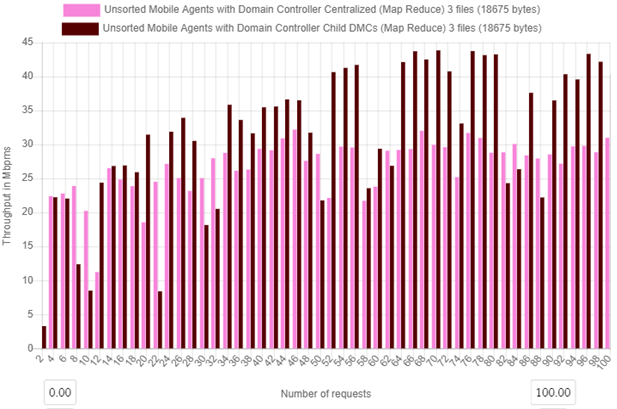
Figure 7a. Throughput over time for centralized and distributed mobile agent controllers with 100 client requests
Figure 7a above shows how the distributed cluster is affects throughput by either centralizing or decentralizing the metadata control and nodes. In the experiment there are 100 client requests are made then their throughput are captured from 2 requests up to the 100 requests.
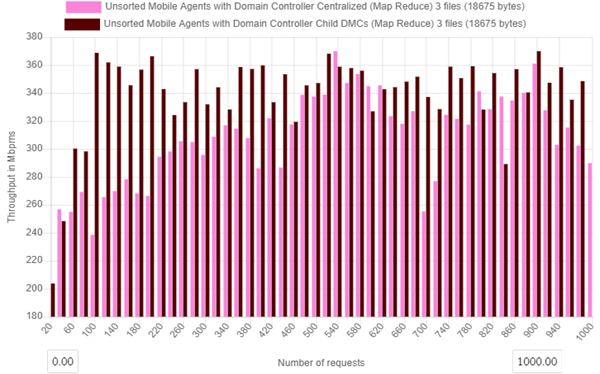
Figure 7b. Throughput over time for centralized and distributed mobile agent controllers with 1000 client requests
Figure 7b above shows how the distributed cluster is affects throughput by either centralizing or decentralizing the metadata control and nodes. In the experiment there are 1000 client requests are made then their throughput are captured from 20 requests up to the 1000 requests.
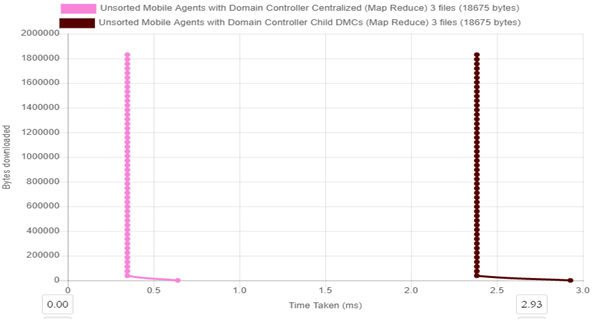
Figure 8a. Scalability over time for centralized and distributed mobile agent controllers with 100 client requests.
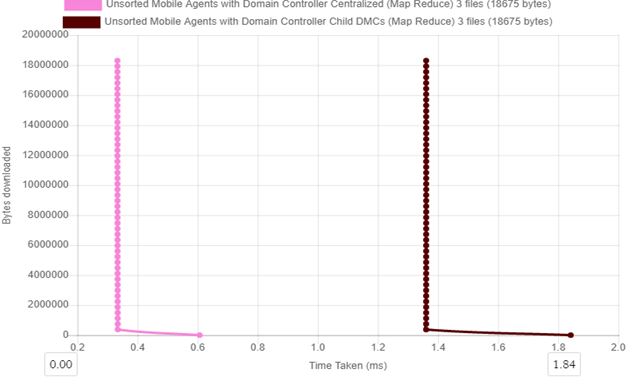
Figure 8b. Scalability over time for centralized and distributed mobile agent controllers with 1000 client requests
Figure 8a and 8b above show how increase in load for both the centralized and distributed agent controllers for 100 and 1000 client requests respectively.
Performance Evaluation
From Figure. 6a and 6b above it can be observed that with the case of 100 client request thread at the 2nd client; for Decentralized agent control Latency= 5221 ms and for Centralized agent control Latency= 1405 ms.
For the case of 1000 client requests at the 20th client request; Decentralized agent control Latency=4015 ms and Centralized agent control Latency=1317ms.
For Decentralized (with child DMCs) agent control the percentage decrease in latency with load increase is 23% and for Centralized agent control percentage decrease in latency with load increase is 6.26 %. We note that the Executions for Latencies are more explicit at the beginning of the threads but overlap as the load increases, hence the reason of choosing the start values for Latency calculations.
For Centralized agent control, throughput at 100 client request for the 100 thread client case Throughput = 31 Mbps and for Decentralized control, Throughput= 42 Mbps as shown in figure 7a.
For Centralized agent control, throughput at 1000 client request for the 1000 thread client case Throughput = 290 Mbps and for Decentralized control, Throughput= 349 Mbps as shown in figure 7b.
Overall considering figure 7a and 7b above, the Decentralized control (with child DMCs) agent percentage decrease in throughput with load increase is 87.97% and for Centralized agent control percentage decrease in throughput with load increase is 89.31 %. There is an observed throughput margin of 1.34 % between the centralized and decentralized agent control.
For figure 8a Centralized agent control Scalability at 100 client request for the 100 client request thread, time to download 1, 830,150 Bytes is 0.35 ms while for Decentralized control, it takes 2.38 ms to download the same size.
For figure 8b Centralized agent control Scalability at 1000 client request for the 1000 client request thread, time to download 18,301,500 Bytes is 0.33 ms while for Decentralized control, it takes 1.36 ms to download the same size.
Overall Decentralized (with child DMCs) agent control percentage increase in Scalability with load increase is 42.86% and for Centralized agent control percentage increase in Scalability with load increase is 5.71%.
Table 4 below show an experiment performed on the DAME engine using one of the files depicted in table 1 above each of which was stored in a single SAN with a single request. Time taken was measured, throughput and Latency respectively while the file size remained constant. The total file size was kept constant at 18675 bytes where SAN 1,2 and 3 each contained 234 bytes,9 bytes and 18432 bytes respectively. The results indicate that the average response time for centralized MA-OSD for 1000 client requests improves from 0.3361 ms to 1.2262 ms indicating a 264.8% improvement in response when the nodes are decentralized. For 100 client request the response time is lower at 0.06 %, which still indicates a marginal positive response time from 0.3230 ms for
centralized MA-OSD to 0.3232 ms for de-centralized MA-OSDs. There is an inverse correlation between the improvement of response times and Latencies; as the response time improves latencies tend to decrease. There is a 152% reduction in latencies for 1000 client requests and 77% reduction in latencies when the load is kept at 100 client requests with de-centralized nodes.
There is a 2 % decrease in throughput when the load is kept 100 client requests when the nodes are decentralized but it improves by 152% for 1000 client requests. This is because the machine takes more time initializing the de-centralization and initialization of mobile agents and metadata procedures and once that is done the machine improves on its performance.
Table 4. CSV Summary
| Parameters | Centralized MA-OSD | De-Centralized MA-OSD | % change with load increase(100 to 1000 file requests) | Total File Size
(Bytes)
|
| AV.TT(ms) 1000 | 0.3361 | 1.2262 | 264.8318 | 18,675 |
| Av.TT(ms) 100 | 0.3230 | 0.3232 | 0.0619 | 18,675 |
| Throughput MB/s 1000 | 21.3160 | 24.2134 | 13.5926 | 18,675 |
| Throughput MB/s 100 | 18.5024 | 18.1039 | -2.1538 | 18,675 |
| AV.Latency(ms) 1000 | 1.3284 | 2.8524 | 152.4000 | 18,675 |
| AV.Latency(ms)100 | 16.2256 | 28.7838 | 77.4000 | 18,675 |
Table 4 above shows the average. Throughput, Latency and Performance (Single file per SAN Request)-SAN1(15 Bytes) +SAN2(684) +SAN3(15 Bytes): SMALL-MEDIUM-SMALL 100/1000 FILE REQUESTS.
CONCLUSION
The results above justify the essence of splitting the serial part of a code section into parallel sections as discussed by [3]. The Decentralized management of agents Improves latencies by up to 23% unlike the centralized ones which reduce it by up to 6% with increase in Load capacity. It is also the decrease in latencies that make distributed agents more scalable since more transaction can be handled per unit time. In the above case when the load was increased the Dentralized agent management scale better by up to 43% while the centralized ones improve by only 6%, hence a margin of 37% shows that the distributed agent environment is highly scalable.
It is also important to observe that the throughput significantly improve whereby the Centralized agent management exhibit a performance margin of 1.34% over the DeCentralized agent model. However, from the observations above in both cases the Decentralized model have higher throughput in the individual cases observed. The decrease in overall throghput could be due to the initialization of the distribution threads and the multiple internal queues maintained by this model.
Application of Mobile agents on a distributed environment [15] is an emerging trend toward the future network managent especially IOT technologies, the results in our experiments show that indeed the agent distribution and decoupling of agent managent and their metadata significantly improve performance of a distributed Network as demontrated theoretically by E. Barsis and Amidal. It is evident that indeed by using a distributed agent model significantly improves performance by substantial margin
Department of Information Technology for equally providing us with platform to setup and run our experiments.
REFERENCES
- Anon (2016) Concordia White paper. Available at: https://www.cis.upenn.edu/bcpierce/629/papers/Concordia-Whitepaper/ (Accessed: 17 March 2016).
- Avilés-González, A., Piernas, J. and González-Férez, P. (2014) ‘Scalable metadata management through OSD+ devices’, International Journal of Parallel Programming,
- Andrei, P. S. et al. (2014) ‘Evolution towards Distributed Storage in a Nutshell’, pp. 1267–1274.
- Alam, M. (2015) ‘Analysis and Clustering of Workload in Google Cluster Trace based on Resource Usage’, (January).
- Docker (2019) Docker Docs. Available at: https://docs.docker.com/v17.09/compose/install/ (Accessed: 27 March 2019).
- Escriv, M., C, J. P. and Bada, G. A. (2014) ‘A Jabber-based Multi-Agent System Platform ∗’, (January 2006). doi: 10.1145/1160633.1160866.
- Essa, Y. M. (2013) ‘Mobile Agent based A New Framework for Improving Big Data Analysis’, (December). doi: 10.1109/CLOUDCOM-ASIA.2013.75.
- FIPA (2002) ‘FIPA Abstract Architecture Specification (SC00001L)’, p. 75.
- Feng, D. et al. (2004) ‘Enlarge Bandwidth of Multimedia Server with Network Attached Storage System 3 The Redirection of Data Transfer’, pp. 489–492.
- Factor, M. et al. (2006) ‘Object Storage: The Future Building Block for Storage Systems A Position Paper’, pp. 119–123. doi: 10.1109/lgdi.2005.1612479.
- Hendricks, J. et al. (2006) ‘Improving small file performance in object-based storage’, (May).
- James (2006) ‘Improving small file performance in object based storage.’, CMU-PDL-06-104.
- M. et al. (2010) ‘A performance evaluation of three Multiagent Platforms’, Artificial Intelligence Review, 34(2), pp. 145–176. doi: 10.1007/s10462-010-9167-9.
- Li, G. et al. (2006) ‘Researches on Performance Optimization of Distributed Integrated System Based on Mobile Agent *’, pp. 4038–4041.
- Lehner, W. (2013) Web-Scale Data Management for the Cloud.
- Mishra, A. (2012) ‘Application of Mobile Agent in Distributed Network Management’. doi: 10.1109/CSNT.2012.198.
- Mesnier, M. et al. (2003) ‘01222722’, (August), pp. 84–90. 42(1), pp. 4–29. doi: 10.1007/s10766-012-0207-8.
- Osero, B. O. (2010) Storage virtualisation and management. University of Nairobi.
- Osero, B. O. (2013) ‘NETWORK STORAGE VIRTUALISATION AND MANAGEMENT BENARD ONG ’ ERA OSERO LECTURER Network Attached Devices , Storage virtualization , Security .’, International Journal of Education and Research, 1(12), pp. 1–10.
- Rajguru, P. (2011) ‘Available Online at www.jgrcs.info ANALYSIS OF MOBILE AGENT’, Journal of Global Research in Computer Science, 2(11), pp. 6–10. Available at: jgrcs.info.
- Rfc, T., Engineering, I., et al. (no date) ‘The RFC 2544 Application – Performance Benchmarking for the HaulPass V60s Link’, pp. 1–11.
- Satoh, I. (2011) ‘Mobile Agent Middleware for Dependable Distributed Systems’.
- Satoh, I. (2014) ‘MapReduce-based Data Processing on IoT’, (iThings). doi: 10.1109/iThings.2014.32.
- Shekhawat, V. S., Gautam, A. and Thakrar, A. (no date) ‘Datacenter Workload Classification and Characterization : An Empirical Approach’.
- Sultana, A. (2015) ‘Using Hadoop to Support Big Data Analysis : Design and Performance Characteristics’.
- Tate, J. et al. (2017) ‘Introduction to Storage Area’.
- Wakefield, R. (2007) ‘An Analysis of Quality of Service Metrics and Frameworks in a Grid Computing Environment’.
- Wang, J. et al. (2010) ‘A Novel Weighted-Graph-Based Grouping Algorithm for Metadata Prefetching A Novel Weighted-Graph-Based Grouping Algorithm for Metadata Prefetching’.
- Yazdi, H. T., Fard, A. M. and Akbarzadeh-T, M. R. (2008) ‘Cooperative criminal face recognition in distributed web environment’, AICCSA 08 – 6th IEEE/ACS International Conference on Computer Systems and Applications, (March), pp. 524–529. doi: 10.1109/AICCSA.2008.4493582.