
Analyzing Public Sentiment and Acceptance of the Bimodal Voter Accreditation System in Nigeria using Sentiment Analysis and RoBERTa Model
- Idi Mohammed
- Zanna Bulama
- 481-491
- Dec 19, 2023
- Computer Science
Analyzing Public Sentiment and Acceptance of the Bimodal Voter Accreditation System in Nigeria using Sentiment Analysis and RoBERTa Model
Idi Mohammed1 & Zanna Bulama2
1Department of Computer Science, Yobe State University, Damaturu. Nigeria
2Department of Computer Science, College of Agriculture, Science, and Technology, Gujba Nigeria
DOI: https://doi.org/10.51244/IJRSI.2023.1011040
Received: 08 November 2023; Accepted: 18 November 2023; Published: 19 December 2023
ABSTRACT
The research article investigates the satisfaction of voters with the deployment of the Bimodal Voter Accreditation System (BVAS) in the 2023 Nigerian presidential election by conducting a sentiment analysis of Twitter posts. The article aims to analyze public opinion and sentiment towards the BVAS system and provide valuable insights that can inform policy decisions and actions related to the implementation and improvement of the system. In this study, Twitter posts related to BVAS and the election were collected using the Twitter streaming API. A total of 997,400 tweets were obtained. The data preprocessing phase involved cleaning the tweets by removing noise, filtering out irrelevant comments, and segmenting the text into words or phrases. The sentiment analysis itself was conducted using the Robustly Optimized BERT Pretraining Approach (ROBERTa), which is a language model introduced by Facebook AI. ROBERTa is a powerful model for sequence modeling and is optimized for sentiment analysis. It predicts the sentiment of each tweet as either positive or negative. This study reveals that attitudes toward the employment of BVAS in the Nigerian presidential election of 2023 are neutral, the acceptance rate is low compared to the rejection rate. Although, there is a large percentage of people who are unfavorable to the introduction of this technology. The study utilized Twitter data exclusively for sentiment analysis, which may limit its accuracy in representing the sentiments of the entire population. Twitter users may not be a fully representative sample and could introduce biases. Additionally, the sentiment analysis focused on English tweets only, potentially overlooking sentiments expressed in other languages spoken in Nigeria, like Hausa, Yoruba, or Igbo. To achieve a more comprehensive analysis, future research could expand to include sentiment analysis of tweets in different languages.
Keywords: Sentiment analysis, Twitter, BVAS, Nigerian election, RoBERTa Model
INTRODUCTION
Since Nigeria’s return to democracy and the beginning of the Fourth Republic in 1999, the Independent National Electoral Commission (INEC) has adopted technology to ensure smooth and credible elections. The latest technology adopted by the commission is the Bimodal Voter Accreditation System (BVAS). BVAS is an electronic device designed to read permanent voter cards (PVCs) and authenticate voters using their fingerprints to verify their eligibility to vote at a specific polling unit. BVAS serves three main functions: 1) verifying the authenticity of Permanent Voter Cards (PVCs); 2) authenticating voters’ fingerprints or faces during accreditation; and 3) instantaneously submitting polling unit results to the INEC Result Viewing Portal (IReV) on Election Day. The BVAS will replace the Z-pad, which was used in previous elections. The Z-Pad was a manual device that was often slow and unreliable. The BVAS is a more efficient and secure device that will help ensure the integrity of the elections. The BVAS has already been used during voter registration, improving the efficiency of the process, and making it easier for people to register to vote. It represents a significant upgrade from the Z-pad and will contribute to the 2023 Nigerian elections being free, fair, and credible.
Utilizing biometrics as a method for verifying and identifying an individual voter entails assessing and evaluating distinct physical or behavioral attributes. These encompass a wide range of biometric characteristics, including fingerprints, voice patterns, palm prints, iris, and retina scans, as well as DNA profiles, which can be measured to ensure authenticity. [1]. To ensure the competence and acceptability of BVAS, feedback from voters and a focus on fixing bugs detected after the election by INEC is necessary. By applying sentiment analysis to the acceptance of the bimodal voter accreditation system in Nigeria, stakeholders can gain valuable insights into public opinion and sentiment towards the system. This can inform policy decisions and actions related to the implementation and improvement of the bimodal voter accreditation system in Nigeria.
In this paper, we use sentiment analysis of Twitter posts to investigate voters’ satisfaction with the deployment of BVAS in the recently concluded 2023 Nigerian presidential election. The paper follows a logical flow, starting with an introduction to the topic, followed by a literature review, methodology, evaluation metrics, experimental results, and a conclusion. It provides relevant background information, explains the research methodology, and presents the findings in a structured manner.
RELATED LITERATURE
Sentiment analysis refers to the process of computationally analyzing and determining the emotional tone, attitudes, opinions, or subjective feelings expressed in a piece of text, such as social media posts, customer reviews, or online comments[1]. It involves using natural language processing (NLP) techniques to classify the sentiment as positive, negative, or neutral, and sometimes even more specific emotions like happiness, anger, or sadness[2]. Sentiment analysis aims to extract and understand the underlying sentiment or subjective information conveyed in textual data, providing valuable insights into people’s opinions and attitudes. Today, Twitter is a well-liked platform for expressing public opinions [3]. Twitter shares people’s psychology, ideas, thinking, behaviors, and sentiment [4]. Research conducted by [5] gives a high-level review of the various approaches and methods used for sentiment analysis-based opinion mining. Microblogging, on the other hand, has received little attention from research or projects based on opinion mining, and the topic of structured political opinion orientation is all but unexplored.
Some of the most significant studies and developments in the field of opinion mining on social media are highlighted Research by [6] provides an overview of the development and current state of sentiment analysis research. It discusses different approaches to sentiment analysis, including lexicon-based, rule-based, and machine learning-based methods, and their applications in various domains. Research conducted by [7] classified opinion into a quintuple consisting of the target, aspect, holder, time and orientation of the opinion. The sentiment lexicon is used to categorize the viewpoint; however, it has the drawback of being domain specific. Proposed system by [8] extracts fine-grained features and associated opinions from online product evaluations to reasonably accurately identify product features. Their system rates based on negative and positive frequency of opinion.
A new approach by [9] classifies emotions of web blog based on the theory of Finite State Automata. They expand the framework of document construction to conceptually depict all observable behaviors exhibited by web services. There mine rules then classified each unit into positive, negative, and neutral categories. Same three categories has been explored by [10] within sentence level opinion classification. Authors in [11] introduced a model that categorizes tweets as either positive, negative, or neutral in relation to a specific political party or party leader handle. This classification was achieved with an accuracy of approximately 59% using a straightforward approach based on the use of a lexicon lookup. Research conducted by [12] shows that it is possible to accurately deduce information about the students’ attitudes from the messages they post on Facebook. They have introduced a fresh approach to Facebook sentiment analysis. On one hand, it provides support for gathering information about the sentiment polarity (positive, neutral, or negative) of users based on their written messages. On the other hand, it enables the modeling of users’ typical sentiment polarity and the identification of significant emotional shifts. Research in [13] develop a Text Based Sentimental Analysis for analyzing public opinion. They presented several reactions which are obtained on any event. These reactions include anger, sadness, happiness, aggressiveness.
There is limited research that has been conducted on sentiment analysis of Nigeria’s 2023 Election data. This research is important for understanding the public’s opinion of the use of BVAS in Nigeria election. Sentiment Analysis of Nigerian 2023 Presidential Election Tweets Using Two-Stage Residual Long Short-Term Memory by [14] used two-stage residual long short-term memory (TSRLSTM) to conduct sentiment analysis of tweets related to the 2023 Nigerian presidential election. The tweets were collected from Twitter and subjected to preprocessing to eliminate extraneous data and irrelevant information. The TRSLSTM model was then used to classify the tweets as positive, negative, or neutral. The results showed that the TRSLSTM model was able to accurately classify the tweets with an accuracy of 92.3%. Another relevant research by [15] used BERT to conduct sentiment analysis of tweets related to the 2023 Lagos State gubernatorial election. The BERT model was then used to classify the tweets as positive, negative, or neutral. The results showed that the BERT model was able to accurately classify the tweets with an accuracy of 93.2%. Research conduction by [16] proposed a sentiment analysis framework for understanding Nigeria’s 2023 presidential election. The framework employed a blend of natural language processing and machine learning methodologies to examine election-related tweets. The results showed that the framework was able to accurately identify the sentiment of the tweets and track the sentiment of the public towards the different candidates. Authors in [17] used sentiment analysis to analyze tweets about the 2023 Nigerian general elections. The study found that most tweets were negative, with a sentiment score of -0.25. The study also found that the most common topics discussed in the tweets were the economy, insecurity, and corruption. Research conducted by [14] compared the performance of different machine learning models in sentiment analysis of tweets related to the 2023 Nigerian presidential election. The study found that the best performing model was the Bidirectional Encoder Representations from Transformers (BERT) model. The study also found that the BERT model was able to accurately classify the sentiment of tweets with an accuracy of 93%.
Extracting user opinions and making informed decisions from unstructured data, which is prevalent on social networks and other platforms, can be a labor-intensive task [18]. Through the utilization of sentiment analysis and text mining approaches to scrutinize the unstructured content present in tweets, it becomes possible to extract valuable insights and uncover latent patterns in diverse real-world situations[19]. Most of the information used in sentiment analysis is gathered from social media sites and is kept in databases known as datasets. However, sentiment analysis gets difficult when the datasets are unbalanced, huge, multi-classed, etc. The evaluation of opinion can be done in two ways [2]: Direct opinion and Comparison mean. In this paper, we adopted direct opinion as it gives a positive or negative opinion about the object directly.
Our literature reviews have been summarized in Table 1 show the most significant studies and developments in the field of opinion mining on social media and sentiment analysis research related to 2023 Nigerian presidential election. The studies show that sentiment analysis can be used to accurately classify the sentiment of tweets, and that this information can be used to understand the public’s opinion of various topics, including elections.
Table 1: Summary of literature review
| Authors | Summary |
| [6] | Gives a high-level review of approaches and methods used for sentiment analysis-based opinion mining. Microblogging and structured political opinion orientation are underexplored. |
| [7] | Offers a comprehensive review of sentiment analysis studies, exploring rule-based, lexicon-based, and machine learning-based methodologies, along with their practical applications. |
| [8] | Classifies opinion into a quintuple of target, aspect, holder, time, and orientation. Utilizes a sentiment lexicon, but with domain specificity limitations. |
| [9] | Extracts fine-grained features and associated opinions from online product evaluations for accurate product feature identification. Uses negative and positive frequency of opinion. |
| [10] | Classifies emotions of web blogs using Finite State Automata theory, representing visible behaviors of web services. Categorizes each unit into positive, negative, and neutral. |
| [11] | Explores positive, negative, and neutral categories within sentence-level opinion classification. |
| [12] | Presents a model for sentiment classification of tweets towards political parties or leaders using a lexicon-based approach, achieving nearly 59% accuracy. |
| [13] | Introduces a fresh approach to sentiment analysis on Facebook, deducing users’ sentiment polarity and detecting emotional changes. |
| [14] | Develops a text-based sentimental analysis to analyze public opinion, considering various reactions such as anger, sadness, happiness, and aggressiveness. |
| [15] | Applies a Two-Stage Residual Long Short-Term Memory (TSRLSTM) model to conduct sentiment analysis on tweets concerning the Nigerian presidential election of 2023, attaining an accuracy rate of 92.3%. |
| [16] | Applies BERT for sentiment analysis of tweets related to the 2023 Lagos State gubernatorial election, achieving an accuracy of 93.2%. |
| [17] | Proposes a sentiment analysis framework for understanding Nigeria’s 2023 presidential election, employing natural language processing and machine learning techniques to analyze tweets. |
| [18] | Uses sentiment analysis to analyze tweets about the 2023 Nigerian general elections, finding mostly negative sentiment with common topics of discussion being the economy, insecurity, and corruption. |
Researchers on sentiment analysis related to the 2023 Nigerian election focus on mining general opinion perspectives instead of focusing on the technology that is regarded as a game-changer in the election process. Most social media users discuss BVAS, which is the technology used, more than any other topic related to the general election. In this research, we focus on mining the opinions of voters regarding the acceptance of BVAS as a tool for voter authentication and result processing.
METHODOLOGY
Several scientific studies have shown that social media may be valuable sources of data for analysis as well as for understanding people’s attitudes and behavior [20]. This section outlines how the dataset for the research originated. Figure 1 and outline the procedure of data gathering.
Data Collection
The data collection was conducted from February to March 2023. Data was scrapped by utilizing Python using Twitter streaming API. A total of 997,400 tweets related to BVAS were obtained. In order to gather relevant data for scientific studies using Twitter messages, either specific keywords or hashtags are used[21]. This data collection process used hashtags related to 2023 Nigerian election. The search key used was “bvas”. Since hashtags are used by users who are somewhat aware of the concepts of trends on Twitter and are thus more experienced than a newbie user, the decision to use keywords instead of hashtags was primarily driven by this logic. We have tried to make our data extracted metadata details with only tweets as is our main aim by eliminating author, location, date, and time connected with tweets by downloading data using keywords.
Data Preprocessing
Twitter user-generated texts need to be cleaned up, the language needs to be normalized, and noisy information needs to be removed because they are informal and dependent on habit [22]. Removing noise from dataset will increase accuracy of sentiment analysis[21]. Data preprocessing involves denoising (deleting from text all arbitrary characters, including punctuation, URL, and digits), filtering (deleting comments that are not significant to the keyword), and segmentation(sentence breaking into words or phrases for text vectorization) [23]. We carried out this process by passing tweets into a function, after the operation, text was returned to data frame using panda in python. The preprocessing function splits the steam text into words, remove any word starting with @ symbol or having length of one character only. Then, the function removes any word starting with http and returns clean text. Emojis, stop words, and functions were all set free from the text.
Sentiment Analysis
With the cleaned data, the text messages are then analyzed and tagged with sentiments using Robustly Optimized BERT Pretraining Approach (ROBERTa) [24] with the help of Python libraries Pandas, Transformers, and snscrape. RoBERTa (Robustly Optimized BERT approach) is a language model introduced by Facebook AI in 2019[25]. BERT and Roberta were created by the Transformers family for sequence modeling to solve long-range dependencies. Roberta Extends Bidirectional Encoder Representation from Transformers (BERT) [26]. The “TweeEval benchmark” is used to optimize the ROBERTa-based model for sentiment analysis[26], which has been pre-trained on 58M tweets. Python’s Transformers module uses NLP to implement Twitter Roberta’s base-sentiment model. ROBERTa allows for trustworthy binary sentiment analysis of several kinds of English-language text[27]. For each instance, it predicts either positive (1) or negative (0) sentiment. Table 2 shows an example of tweets labeled with positive, neutral, and negative.
Table 2: Example of tweets labeled with Positive, Neutral, and Negative
| S/No | Tweets | Label |
| 1 | were the senatorial and the house of representative’s elections uploaded in the bvas yes or no animal surfer kill u there | -1 |
| 2 | if you have nothing to hide why the delayed in allowing the eluu p and pdp to go through the bvas all this while | 0 |
| 3 | my dearly beloved president in the waiting you are very correct some of us have started the reconfiguration of our bvas remain blessed sir | 1 |
Feature Extraction
The bag-of-words approach is a text modeling technique utilized in Natural Language Processing. Bag of Words is a technique for extracting features from text data by turning the text into numerical vectors. Those numbers are the count of each word (token) in a document. Bag of words has been applied to feature extraction[28].
Training Datasets
RoBERTa performs downstream tasks very similarly to BERT, from token processing through target class prediction. Although the RoBERTa model is built upon the BERT framework, it diverges significantly in terms of the pre-training process to enhance its performance. Auto Model for Sequence Classification from pretrained Roberta are imported from the cardiffnlp for twitter-roberta-base-sentiment library which was trained on ~198M tweets was used for classification.
System Architecture
Figure 1 shows the proposed system architecture. The first step is for the user to specify input keywords for data collection. The keyword is used to collect tweets using Twitter API v2. The collected tweets were stored in csv file and then passed to data pre-processing steps. Case folding, remove non-letter characters, removing words starting with HTTP, & removing stop words operations are performed at pre-processing step. The pre-processed stream of text will pass through feature extraction using bag-of-words model. System analysis process with ROBERTa model test individual character from stream of text and label the sentence with either positive, neutral, or positive before passing the result to user.
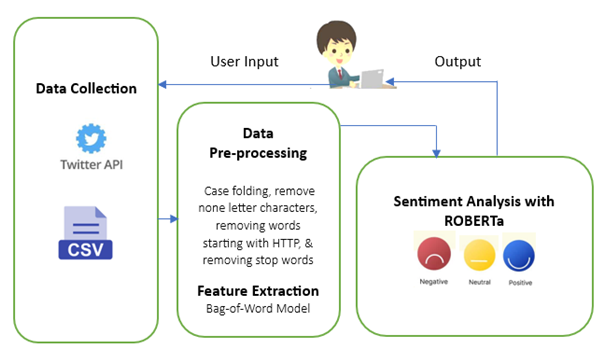
Figure 1: Proposed System Architecture
Evaluation Metrics
The assessment of different Transformer-based pre-trained models utilized in the study primarily relies on metrics such as training, testing, and validation accuracy for evaluation. The model’s performance is also compared using Precision, Recall, and F1 score.
Accuracy
Accuracy is the measure of the rightness of a model. It is often determined by the ratio of the number of accurate categories to the total number of classifications. To assess how the model performs for a single training period, training accuracy is frequently utilized[29]. The model’s accuracy during the test is its accuracy following thorough training.
Accuracy= (TP+TN)/(TP+FP+TN+FN) (1)
Where TP stands for: True Positive, TN True Negative, FP False Positive, and FN False Negative.
Precision
The number of accurate positive predictions made by the model is known as precision. How well the model predicts Positive labels is indicated by its precision value. Better precision results from fewer false positives. The model is considered to be at its optimal performance level when the precision value reaches 1[29].
precision= TP/(TP+FP) (2)
Recall
The recall is the proportion of all relevant outcomes accurately categorized by models. More positive samples are found when recall is higher.
recall= TP/(TP+FN) (3)
F1 score
Although the F1 score is frequently thought of as accuracy, a model’s accuracy mostly depends on the number of True Negatives. When target labels are distributed unevenly across the data, the F1 score is very helpful.
F1 score =2 x (precession x recall)/(precession+ recall) (4)
EXPERIMENTAL RESULTS AND DISCUSSION
Visualization of data is frequently advantageous in sentiment analysis as it aids in comprehending the outcomes. [30]. A total number of distinct words 3,334 were found in the original source. The most prominent words are “bvas”, “nigerians”, “nigeria”, “inec” and “court”. The highest frequency word is 584 while the minimum frequency is 22. Figure 2 displays word clouds, which are visual representations of the frequency of words in a text. The size of the word in the cloud is proportional to its frequency in the text. Word clouds can be used to identify the most important words in a text, or to explore the themes of a text. We then utilize the R package to visualize the most dominants feature as shown in figure 3.
This study reveals that attitudes on the employment of BVAS in the Nigerian presidential election of 2023 is neutral, the acceptance rate is low compared to rejection rate. Although, there is a large percentage of people who are unfavorable with the introduction of this technology. RoBERTa has demonstrated excellent performance on sentiment analysis tasks.

Figure 2: Word Cloud of the Prevalent Terms
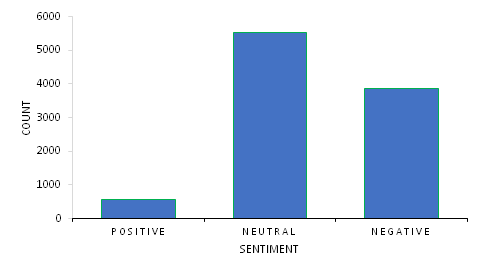
Figure 3: Plot of Sentiment Polarities of Voters perception on the use of BVAS
It has outperformed previous state-of-the-art models and achieved competitive results on various sentiment analysis benchmarks. By leveraging its contextual understanding and semantic representations, RoBERTa can effectively capture sentiment information in text. However, in general, RoBERTa has achieved state-of-the-art or competitive performance on various sentiment analysis benchmarks.
Table 2: Performance metrics for the models on the dataset of BVAS
| Models | Accuracy | Precision | Recall | F-Score |
| BERT | 73.78% | 71.40% | 79.34% | 75.16% |
| RoBERTa | 87.56% | 88.31% | 91.33% | 90.12% |
| GPT | 86.22% | 82.43% | 87.65% | 85.56% |
| XLNet | 71.40% | 69.22% | 72.35% | 70.01% |
| ALBERT | 82.16% | 80.87% | 84.97% | 84.39% |
| ELECTRA | 75.31% | 82.07% | 80.17% | 79.81% |
For example, in the Sentiment140 dataset, which consists of tweets labeled as positive or negative sentiment, RoBERTa has achieved accuracy scores in the range of 80% to 90% in different studies.
This study compares the performance of RoBERTa in terms of BVAS discussion with other sentiment analysis models that perform similarly to RoBERTa in terms of sentiment analysis tasks. As shown in table 2, The lineup of models consists of BERT, GPT, XLNet, ALBERT, and ELECTRA.
CONCLUSION
The acceptance rate of the Bimodal Voter Accreditation System (BVAS) in the Nigerian presidential election of 2023 was low, with a significant percentage of people expressing unfavorable opinions about the technology. Sentiment analysis using the RoBERTa model proved to be an effective approach for understanding public sentiment and guiding policy decisions regarding the implementation and improvement of the BVAS in Nigeria. The RoBERTa model demonstrated excellent performance in sentiment analysis tasks, outperforming previous state-of-the-art models and achieving competitive results on various sentiment analysis benchmarks.
The study relies solely on Twitter data for sentiment analysis. While Twitter can provide valuable insights into public opinion, it may not represent the views of the entire population accurately. The analysis could be biased towards users who are active on Twitter and may not capture the sentiment of the broader population. Finally, the sentiment analysis using RoBERTa was performed on English tweets only. It may not capture sentiments expressed in other languages spoken in Nigeria, such as Hausa, Yoruba, or Igbo. The research could be extended to include sentiment analysis of tweets in different languages to provide a more comprehensive analysis.
REFERENCE
- M. Agarwal and S. K. Pant, “A Study of Sentiments of Employees during COVID-19.” [Online]. Available: http://publishingindia.com/tbr/
- N. Mishra and C. K. Jha, “Classification of Opinion Mining Techniques,” Int. J. Comput. Appl., vol. 56, no. 13, pp. 1–6, 2012, doi: 10.5120/8948-3122.
- S. Jain, V. Sharma, and R. Kaushal, “PoliticAlly: Finding political friends on twitter,” Int. Symp. Adv. Networks Telecommun. Syst. ANTS, vol. 2016-Febru, no. October 2016, 2016, doi: 10.1109/ANTS.2015.7413659.
- E. Georgiadou, S. Angelopoulos, and H. Drake, “Big data analytics and international negotiations: Sentiment analysis of Brexit negotiating outcomes,” Int. J. Inf. Manage., vol. 51, no. October, p. 102048, 2020, doi: 10.1016/j.ijinfomgt.2019.102048.
- J. Prager, “Open-domain question-answering,” Found. Trends Inf. Retr., vol. 1, no. 2, pp. 91–233, 2006, doi: 10.1561/1500000001.
- L. Pang, B., & Lee, “Opinion mining and sentiment analysis,” Found. trends Inf. Retr., vol. 2, pp. 1–2, 2008.
- S. Moghaddam and M. Ester, “Opinion Mining in Online Reviews: Recent Trends,” Simon Fraser Univ. Tutor. WWW2013, 2013, [Online]. Available: http://www.cs.sfu.ca/~ester/papers/WWW2013.Tutorial.Final.pdf
- N. Anwer, A. Rashid, and S. Hassan, “Feature based opinion mining of online free format customer reviews using frequency distribution and Bayesian statistics,” Proceeding – 6th Int. Conf. Networked Comput. Adv. Inf. Manag. NCM 2010, no. May 2014, pp. 57–62, 2010.
- C. Yang, K. H. Y. Lin, and H. H. Chen, “Emotion classification using web blog corpora,” Proc. IEEE/WIC/ACM Int. Conf. Web Intell. WI 2007, pp. 275–278, 2007, doi: 10.1109/WI.2007.50.
- S. M. Kim and E. Hovy, “Determining the sentiment of opinions,” COLING 2004 – Proc. 20th Int. Conf. Comput. Linguist., no. May, 2004, doi: 10.3115/1220355.1220555.
- A. Aggarwal, K. Maurya, and A. Chaudhary, “Comparative Study for Predicting the Severity of Cyberbullying Across Multiple Social Media Platforms,” Proc. Int. Conf. Intell. Comput. Control Syst. ICICCS 2020, no. Iciccs, pp. 871–877, 2020, doi: 10.1109/ICICCS48265.2020.9121046.
- A. Ortigosa, J. M. Martín, and R. M. Carro, “Sentiment analysis in Facebook and its application to e-learning,” Comput. Human Behav., vol. 31, no. 1, pp. 527–541, 2014, doi: 10.1016/j.chb.2013.05.024.
- P. Agarwal, “Developing an Approach to Evaluate and Observe Sentiments of Tweets,” Int. J. Sci. Res. Comput. Sci. Eng. Inf. Technol., vol. 5, no. 3, pp. 473–479, 2019, doi: 10.32628/cseit1953143.
- D. O. Oyewola, L. A. Oladimeji, S. O. Julius, L. B. Kachalla, and E. G. Dada, “Optimizing sentiment analysis of Nigerian 2023 presidential election using two-stage residual long short term memory,” Heliyon, vol. 9, no. 4, p. e14836, 2023, doi: 10.1016/j.heliyon.2023.e14836.
- A. Wusu, O. Olabanjo, R. Padonu, and M. Mazzara, “Twitter Sentiment Analysis of Lagos State 2023 Gubernatorial Election using BERT,” no. March, pp. 1–16, 2023, doi: 10.20944/preprints202303.0335.v1.
- O. Olabanjo et al., “From Twitter to Aso-Rock: A Natural Language Processing Spotlight for Understanding Nigeria 2023 Presidential Election,” no. October 2022, 2022, doi: 10.20944/preprints202210.0238.v1.
- A. Ogunsanwo, O.; Adewole, “Sentiment analysis of twitter data for the 2023 Nigerian general elections,” Cogent Eng., vol. 10, no. 1, 2023.
- M. T. H. K. Tusar and M. T. Islam, “A Comparative Study of Sentiment Analysis Using NLP and Different Machine Learning Techniques on US Airline Twitter Data,” Proc. Int. Conf. Electron. Commun. Inf. Technol. ICECIT 2021, no. January 2022, 2021, doi: 10.1109/ICECIT54077.2021.9641336.
- S. Mansour, “Social media analysis of user’s responses to terrorism using sentiment analysis and text mining,” Procedia Comput. Sci., vol. 140, pp. 95–103, 2018, doi: 10.1016/j.procs.2018.10.297.
- C. Langos, “Cyberbullying: The challenge to define,” Cyberpsychology, Behav. Soc. Netw., vol. 15, no. 6, pp. 285–289, 2012, doi: 10.1089/cyber.2011.0588.
- U. Yaqub, V. Atluri, S. A. Chun, and J. Vaidya, “Sentiment based Analysis of Tweets during the US Presidential Elections,” ACM Int. Conf. Proceeding Ser., vol. Part F1282, no. November 2018, pp. 1–10, 2017, doi: 10.1145/3085228.3085285.
- H. T. Duong, T. Anh, and N. Thi, “A review : preprocessing techniques and data augmentation for sentiment analysis,” Comput. Soc. Networks, vol. 8, no. 1, pp. 1–16, 2021, doi: 10.1186/s40649-020-00080-x.
- X. Zhang and X. Qin, “Research on Sentiment Analysis Algorithm for Comments on Online Ideological and Political Courses,” vol. 13, no. 11, pp. 174–179, 2022.
- Y. Liu et al., “RoBERTa: A Robustly Optimized BERT Pretraining Approach,” no. 1, 2019, [Online]. Available: http://arxiv.org/abs/1907.11692
- V. S. Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, “A Robustly Optimized BERT Pretraining Approach,” A Robustly Optimized BERT Pretraining Approach, 2018.
- U. Sirisha and B. S. Chandana, “Aspect based Sentiment and Emotion Analysis with,” vol. 13, no. 11, 2022.
- Jochen Hartmann; Mark Heitmann and Christian Siebert, “More than a Feeling: Accuracy and Application of Sentiment Analysis,” Int. J. Res. Mark., vol. 2023, no. 1, pp. 75–87, 2023.
- S. Hajar, A. Samsudin, N. M. Sabri, N. Isa, U. Fatihah, and M. Bahrin, “Sentiment Analysis on Acceptance of New Normal in COVID-19 Pandemic using Naïve Bayes Algorithm,” vol. 13, no. 9, pp. 581–588, 2022.
- G. Reddy Narayanaswamy, “Exploiting BERT and RoBERTa to Improve Performance for Aspect Based Sentiment Analysis,” 2021, doi: 10.21427/3w9n-we77.
- I. Steinke, J. Wier, L. Simon, and R. Seetan, “Sentiment Analysis of Online Movie Reviews using Machine Learning,” vol. 13, no. 9, pp. 618–624, 2022.